
План
- Введение
- Асинхронность и многопоточность
- Потоки в Android
- Thread и Runnable
- Looper и Handler
- HandlerThread
- AsyncTask
- Loader и LoaderManager
- Executor
- RxJava
- Kotlin Coroutines
- Заключение
Введение

Исторически сложилось, что разработчик пишет последовательный код. Программа выполняет такой код строчка за строчкой в соответствии с написанным. То есть, когда вызывается какая-либо функция, которая выполняет длительную операцию, то программа должна дождаться её окончания и затем продолжить следующую строчку кода.
Однако с развитием технологий современные системы научились обрабатывать множество задач одновременно. Теперь программа может вынести выполнение такой функции отдельно и продолжить выполнять следующие строчки кода, не дожидаясь результата работы функции.
Это стало возможно благодаря двум ключевым механизмам: асинхронности и многопоточности.
Асинхронность и многопоточность
Под асинхронностью понимается подход, когда результат выполнения задачи доступен не сразу, а через некоторое время в виде некоторого асинхронного вызова. Концепция асинхронного программирования нарушает обычный порядок выполнения программы, позволяя не ожидать результат выполнения операции и не блокировать дальнейшее выполнение программы.
Многопоточность же это свойство приложения, заключающееся в том, что процесс, созданный в операционной системе, может состоять из нескольких потоков, выполняющихся «параллельно». Благодаря этому можно выполнять сразу несколько операций, вынесенных в отдельные потоки, что позволяет более эффективно использовать ресурсы устройства и ускорить работу приложения.
Асинхронность и многопоточность тесно связаны друг с другом. По сути мы делегируем задачу отдельному потоку, который вернёт результат работы через некоторое время.
Благодаря этим механизмам мы можем максимально задействовать все ресурсы устройства и писать сложные приложения, ежесекундно выполняющие множество операций.
Потоки в Android
В Android-разработке, как и в большинстве других областей программирования, часто возникают задачи по выполнению каких-либо трудоёмких или длительных операций. К таким операциям можно отнести выполнение запросов к серверу (и в целом сетевые запросы), загрузка большого количества изображений, обращение к базе данных, чтение/запись в файловую систему и т.п. Неправильная работа с такими операциями может привести к плохой работе приложения или даже к полному его отказу.
Корень проблемы здесь кроется в том, что в Android-приложении всё завязано на главном потоке. При запуске приложения система создаёт новый процесс с одним потоком, который является точкой входа в приложение. Этот поток и называется «главный поток«. Задачей главного потока является отрисовка/обновление UI и обработка событий. Поскольку практически всё взаимодействие пользователя с приложением происходит через UI, то главный поток также является UI-потоком.
При выполнении длительных операций на главном потоке может возникнуть следующая ситуация: главный поток не может отрендерить UI, поскольку занят выполнением других задач. Долгое ожидание в главном потоке в итоге приведёт к ошибке ANR (Application Not Responding — Приложение не отвечает) и остановке системой процесса с приложением.
Чтобы избежать подобного, в процессе Android-разработки необходимо убирать все тяжёлые задачи из главного потока. Здесь и приходят на помощь асинхронность и многопоточность. Благодаря им мы можем выполнять длительные операции, не нагружая основной поток и не провоцируя «зависание» приложения.
В Android существует множество различных инструментов, помогающих реализовывать в приложении многопоточность. В этой статье мы рассмотрим как уже устаревшие, так и современные решения.
Thread и Runnable
Класс Thread является базовым классом в Android для создания многопоточности. Он уже содержит в себе всё необходимое для работы и предоставляет простой API.
Для того, чтобы определить новый поток, достаточно создать экземпляр класса Thread, затем передать в него объект, реализующий интерфейс Runnable. Сделать это можно разными способами:
- Создаём класс, наследующий от Thread. В этом случае мы не передаём объект Runnable и поэтому при запуске вызывается метод Thread.run(), который мы и переопределили.
// Первый способ
class MyThread : Thread() {
override fun run() {
// Код
}
}
val thread = MyThread()
thread.start()- Создаём объект, реализующий интерфейс Runnable, затем передаём его в конструктор Thread(Runnable).
// Второй способ
class MyRunnable : Runnable {
override fun run() {
// Код
}
}
val thread = Thread(MyRunnable())
thread.start()- С помощью функции стандартной библиотеки Kotlin. Если посмотреть исходники данной функции, то она делает всё тоже самое, что и предыдущие способы, но в более лаконичном и удобном для чтения виде.
thread {
// Код
}Интерфейс Runnable содержит всего один метод run(). Этот метод мы должны переопределить и написать внутри него код, который будет выполняться в потоке.
К примеру, создадим новый объект Thread, который будет ожидать 5 секунд, после чего отправит в главный поток тост с приветствием.
thread(name = "Test Thread") {
Thread.sleep(5000)
val name = Thread.currentThread().name
runOnUiThread {
Toast.makeText(this, "Hello from $name", Toast.LENGTH_SHORT).show()
}
}Для удобства мы также задали имя потоку, чтобы его можно было легко определить среди остальных.
Чтобы запустить поток, нужно вызвать метод Thread.start(). В результате этого вызова система создаст новый поток, внутри которого будет выполняться кусок кода, определённый в run().
Примечание: в случае вызова thread { } из стандартной библиотеки Kotlin, необходимости вызывать Thread.start() нет. Метод автоматические вызовется, если не передать дополнительно в функцию параметр start.
Чтобы принудительно остановить поток, нужно вызвать метод Thread.interrupt(), однако делать это следует осторожно. В различных ситуациях метод может привести к исключениям SecurityException, InterruptedExteption или ClosedByInterruptException, которые нужно будет корректно обработать.
Также можно объявить поток демоном (в Linux-среде демоном (”daemon”) называют процесс, который работает в фоновом режиме без прямого участия пользователя). В этом случае поток будет завершён при завершении главного потока приложения. Однако делать это нужно до запуска потока, в противном случае мы получим исключение IllegalStateThreadException.
thread.isDaemon = true
thread.start()SecurityException может возникнуть, как правило, если у текущего потока нет прав на изменение другого потока. Проверить наличие прав можно с помощью метода Thread.checkAccess().
Также потоку можно задать приоритет (от 1 до 10) с помощью метода Thread.setPriority(Int). В зависимости от заданного приоритета система определяет важность запущенного потока и может выполнить его раньше других потоков с более низким приоритетом.
Запустив приложение, мы видим, что сообщение с приветствием появляется спустя некоторое время после запуска.

Если обратиться к Profiler, встроенному в Android studio, и запустить профилирование, мы увидим, что наш поток спал 5 секунд, после чего выполнил строчку кода с вызовом Toast и уничтожился.
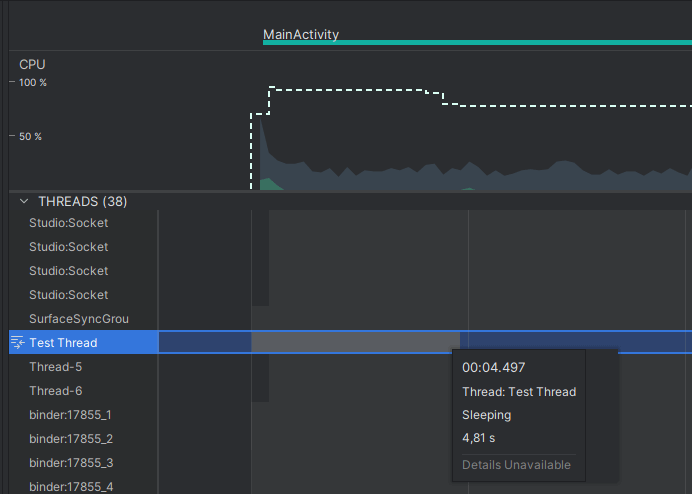
Как можно видеть, класс Thread предоставляет удобный и простой инструмент для создания потоков.
К его достоинствам можно отнести следующее:
- Предоставляет полный контроль над созданием и вызовом потока.
- Подходит для выполнения длительных задач, требующих продолжительной обработки.
- Может использоваться для выполнения сложных операций, требующих низкоуровневый контроль над потоками.
Однако Thread имеет и ряд недостатков:
- Для управления потоками нужно будет писать много кода.
- Не предоставляет методов для обновления UI с выводом результата работы. Для этого нужно использовать способы, предложенные в примечании ниже.
- Неправильное использование может привести к проблемам с параллелизмом.
Важно! В примере указан вызов Toast указан внутри специального метода runOnUiThread(Runnable). Если мы попробуем убрать его и показать тост, то приложение будет остановлено со следующей ошибкой:
FATAL EXCEPTION: Test Thread
Process: ru.androidtools.multithreadtest, PID: 15543
java.lang.NullPointerException: Can't toast on a thread that has not called Looper.prepare()
at com.android.internal.util.Preconditions.checkNotNull(Preconditions.java:168)
at android.widget.Toast.getLooper(Toast.java:186)
at android.widget.Toast.<init>(Toast.java:171)
at android.widget.Toast.makeText(Toast.java:502)
at android.widget.Toast.makeText(Toast.java:491)
at ru.androidtools.multithreadtest.MainActivity$createThread$thread$1.run(MainActivity.kt:29)Эта ошибка говорит о том, что для показа Toast нужно проинициализировать в потоке Looper (класс, используемый для обработки сообщений, подробнее мы рассмотрим его далее в статье). По умолчанию Looper есть только у главного потока, поэтому вызов Toast нужно выполнить в нём. Кроме того, любое другое взаимодействие с UI нужно выполнять только в UI-потоке. Для того, чтобы вызвать код из потока в UI-потоке, есть несколько способов:
- Looper-Handler
У главного потока есть собственный Looper. В этот Looper можно отправить Runnable, содержащий код, который будет выполнен в UI-потоке. Для взаимодействия с Looper и отправки сообщений используется класс Handler, в параметры которому нужно передать Looper. В данном случае это будет Looper главного потока, полученный с помощью метода Looper.getMainLooper(). Создадим экземпляр класса Handler и внутри потока вызовем у него метод post(Runnable), который и отправит сообщений в Looper.
val handler = Handler(Looper.getMainLooper())
val thread: Thread = object : Thread() {
override fun run() {
sleep(5000)
handler.post {
Toast.makeText(this@MainActivity, "Hello from $name", Toast.LENGTH_SHORT).show()
}
}
}
thread.start()- Activity.runOnUiThread(Runnable)
Также можно воспользоваться методом Activity.runOnUiThread, который (аналогично Handler), передаёт в UI-поток Runnable, содержащий кусок кода для выполнения. В этом случае код будет выглядеть как в изначальном примере.
Оба способа работают по одному принципу: отправляют сообщение в очередь сообщений UI-потока, которые затем их обрабатывает. Таким образом, если вы хотите взаимодействовать с UI из потока, то следует это делать через связку Looper-Handler, либо Activity.runOnUiThread().
Looper и Handler
Иногда возникает необходимость передать сообщение из одного потока в другой. Для этого можно воспользоваться классами Looper и Handler.
Looper — это класс, который сохраняет поток живым, добавляя в него очередь сообщений MessageQueue. Он просматривает сообщения в MessageQueue и отправляет их в Handler для обработки обратных вызовов. Сообщениями могут быть как различные объекты, так и Runnable, содержащие куски кода для выполнения.
Handler — класс, который занимается организацией очереди сообщений.
В отличие от обычного потока, поток с запущенным в нём Looper будет работать до тех пор, пока его не остановят.
Выше мы рассматривали, как из потока можно выполнить код в главном потоке, и как пример приводилось использование Looper. Это объясняется тем, что у главного потока по умолчанию есть свой собственный Main Looper, который и поддерживает работу главного потока. Благодаря ему мы можем посылать в главный поток различные сообщения, а также выполнять обновление UI из потока.
Напишем небольшой пример, создающий два потока. Один поток будет работать с Looper внутри и принимать сообщения, а второй после небольшого ожидания отправит сообщение в первый поток и завершит свою работу.
class LooperThread : Thread() {
lateinit var handler: Handler
override fun run() {
val threadName = name
Looper.prepare()
handler = Handler(Looper.myLooper()!!) { message ->
val messageName = message.obj as String
runOnUiThread {
Toast.makeText(
this@MainActivity,
"$threadName send hello from $messageName",
Toast.LENGTH_SHORT
).show()
}
true
}
Looper.loop()
}
}
val looperThread = LooperThread()
looperThread.name = "Test Thread 1"
looperThread.start()
thread(name = "Test Thread 2") {
Thread.sleep(3000)
val message = Message.obtain().apply {
obj = currentThread().name
}
looperThread.handler.sendMessage(message)
}
Для того, чтобы создать очередь сообщений в потоке, нам нужно выполнить несколько действий:
- Вызвать метод Looper.prepare(). Этот метод проинициализирует Looper в текущем потоке и подготовит очередь сообщений.
- Создать Handler, который будет связан с этим Looper. Чтобы получить наш созданный Looper, нужно воспользоваться методом Looper.myLooper(), который возвращает связанный с текущим потоком Looper, если таковой есть.
- Вызвать метод Looper.loop(), который запускает в потоке просмотр очереди сообщений.
После этого мы можем отправлять в поток сообщения. Чтобы это сделать, нам понадобится создать экземпляр класса Message, в который можно помещать любые необходимые данные или куски кода для выполнения. В данном случае мы хотим в Message передать имя потока, который отправил сообщение. Чтобы сообщение дошло до нужного потока, воспользуемся Handler из первого потока и вызовем у него метод Handler.sendMessage(Message), который посылает сообщение в очередь сообщений.
Looper увидит, что в очереди появилось новое сообщение, и передаст его на обработку в Handler, с которым связан. Чтобы Handler мог разобрать входящее сообщение, ему нужно переопределить метод handleMessage(Message), внутри которого мы и будем разбирать данные из сообщения.
Когда нужно остановить поток с Looper, то следует вызвать метод Looper.quit().
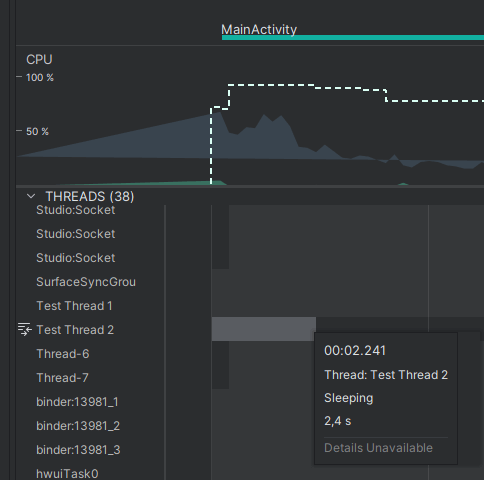
Если обратиться к профайлеру, то можно увидеть, как Test Thread 2 “спал” в течение 3 секунд, после чего отправил сообщение и завершил свою работу, а Test Thread 1 в свою очередь продолжает работать до тех пор, пока его не остановят.
HandlerThread
Выше мы рассмотрели случай, когда к потоку можно добавить Looper для обработки очереди сообщений. Однако в Android уже есть готовая реализация такого потока под название HandlerThread.
Класс HandlerThread наследует от Thread и представляет собой обёртку, которая автоматически создаёт Looper и настраивает очередь сообщений.
При инициализации HandlerThread внутри вызывается всё тот же Looper.prepare(), после чего вызывается специальный метод HandlerThread.onLooperPrepared(). По умолчанию этот метод пустой, но его можно переопределить в случае, если нужно произвести дополнительную настройку перед запуском Looper. Затем вызывается Looper.loop() и поток начинает ожидать входящие сообщения.
Таким образом, основная реализация лежит на HandlerThread, от нас требуется только объявить Handler и связать его с Looper.
HandlerThread также содержит в себе такие методы, как HandlerThread.quit() и HandlerThread.quitSafely(), которые останавливают поток и под капотом вызывают Looper.quit(). Различие между этими двумя методами в том, что quit() завершает работу, не дожидаясь обработки всех сообщений в очереди, а quitSafely() — только после того, как очередь сообщений будет обработана.
В остальном же с HandlerThread можно работать так же, как и с обычным Thread.
Возьмём предыдущим пример с Looper и попробуем его переписать с использованием HandlerThread.
val handlerThread = HandlerThread("Test Handler Thread")
handlerThread.start()
val handler = Handler(handlerThread.looper) { message ->
val messageName = message.obj as String
Toast.makeText(
this@MainActivity,
"${currentThread().name} send hello from $messageName",
Toast.LENGTH_SHORT
).show()
true
}
thread(name = "Test Thread 2") {
Thread.sleep(3000)
val message = Message.obtain().apply {
obj = currentThread().name
}
handler.sendMessage(message)
}Как можно видеть, главным отличием здесь является то, что теперь мы не заботимся об инициализации Looper.

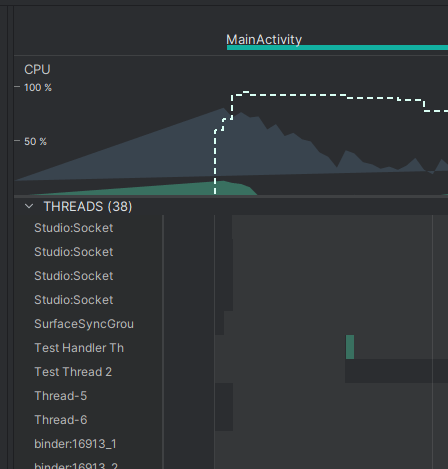
В профайлере ситуация также схожа с предыдущим примером: Test Thread 2 отправил сообщение и завершился, в то время как Test Handler Thread это сообщение получил, обработал, и продолжил ожидать дальнейшие сообщения.
Попробуем усложнить пример. Создадим свой класс, наследующий от HandlerThread, который будет принимать запросы на загрузку изображений, обрабатывать их, и возвращать результат в главный поток.
Для этого создадим класс и назовём его, допустим, ImageHandlerThread.
class ImageHandlerThread(
private val responseHandler: Handler,
private val listener: ThreadListener
) : HandlerThread("Images Handler Thread") {
interface ThreadListener {
fun onImageDownloaded(target: T, image: Bitmap)
}
private lateinit var requestHandler: Handler
private val requestMap: ConcurrentHashMap<T, String> = ConcurrentHashMap()
override fun onLooperPrepared() {
requestHandler = Handler(looper) { message ->
if (message.what == MESSAGE_DOWNLOAD) {
@Suppress("UNCHECKED_CAST")
val target = message.obj as T
handleRequest(target)
true
} else {
false
}
}
}
fun queueImage(target: T, link: String) {
requestMap[target] = link
requestHandler.obtainMessage(MESSAGE_DOWNLOAD, target).sendToTarget()
}
fun clearQueue() {
requestHandler.removeMessages(MESSAGE_DOWNLOAD)
requestMap.clear()
}
private fun handleRequest(target: T) {
val link = requestMap[target] ?: return
val bitmap = loadImage(link) ?: return
responseHandler.post {
val result = requestMap[target]
if (result == null || result != link) return@post
requestMap.remove(target)
listener.onImageDownloaded(target, bitmap)
}
}
private fun loadImage(link: String): Bitmap? {
val url = URL(link)
var connection: HttpURLConnection? = null
return try {
connection = url.openConnection() as HttpURLConnection
connection.connect()
val bufferedInputStream = BufferedInputStream(connection.inputStream)
BitmapFactory.decodeStream(bufferedInputStream)
} catch (e: IOException) {
null
} finally {
connection?.disconnect()
}
}
companion object {
const val MESSAGE_DOWNLOAD = 101
}
} Здесь используются два экземпляра Handler: один привязан к Looper нашего потока и нужен для отправки сообщений в поток, а второй привязан к Looper главного потока и служит для возвращения результата работы.
Для того, чтобы присоединить Handler к нашему Looper, переопределён метод HandlerThread.onLooperPrepared(), где и происходит инициализация обработчика.
Также мы объявили HashMap<T, String>, в котором будут храниться поступающие запросы.
Метод queueImage(T, String) используется для отправки нового сообщения в поток.
Метод loadImage(String) реализует стандартную загрузку файла из Интернета с помощью класса HttpURLConnection.
Также нам понадобится какой-то список, который мы будем загружать. Для отображения списка воспользуемся RecyclerView и напишем для него простой адаптер.
class ImagesAdapter(
private val images: List,
private val imageHandlerThread: ImageHandlerThread
) : RecyclerView.Adapter() {
override fun getItemCount(): Int = images.count()
override fun onCreateViewHolder(
parent: ViewGroup,
viewType: Int
) = ImageHolder(
ItemImageBinding.inflate(
LayoutInflater.from(parent.context),
parent,
false
)
)
override fun onBindViewHolder(
holder: ImageHolder,
position: Int
) = super.onBindViewHolder(holder, position, emptyList())
override fun onBindViewHolder(
holder: ImageHolder,
position: Int,
payloads: List
) {
if (payloads.isNotEmpty()) {
for (payload in payloads) {
if (payload is ImagePayload) {
holder.updateImage(payload.image)
}
}
} else {
val image = images[position]
holder.bind()
imageHandlerThread.queueImage(position, image)
}
}
fun updateItem(position: Int, image: Bitmap) {
val imagePayload = ImagePayload(image)
notifyItemChanged(position, imagePayload)
}
class ImageHolder(
private val binding: ItemImageBinding
) : RecyclerView.ViewHolder(
binding.root
) {
fun bind() = showProgress()
fun updateImage(image: Bitmap) {
hideProgress()
binding.ivImage.setImageBitmap(image)
}
private fun showProgress() {
binding.ivImage.visibility = View.INVISIBLE
binding.progressLoading.visibility = View.VISIBLE
}
private fun hideProgress() {
binding.ivImage.visibility = View.VISIBLE
binding.progressLoading.visibility = View.GONE
}
}
private data class ImagePayload(val image: Bitmap)
} В методе onBindViewHolder() мы проверяем наличие payloads. Если их нет, значит ячейку надо проинициализировать и отправить в ImageHandlerThread запрос на загрузку изображения для этой ячейки. В противном случае payloads будет содержать Bitmap с загруженной картинкой, которую нужно установить в ячейку.
Код фрагмента с объявлением ImageHandlerThread и созданием списка представлен ниже:
class HandlerThreadFragment : Fragment() {
private var _binding: FragmentHandlerThreadBinding? = null
private val binding get() = _binding!!
private val imageHandlerThread: ImageHandlerThread = ImageHandlerThread(
Handler(Looper.getMainLooper()),
object : ImageHandlerThread.ThreadListener {
override fun onImageDownloaded(target: Int, image: Bitmap) {
imagesAdapter.updateItem(target, image)
}
}
)
private val imagesAdapter: ImagesAdapter = ImagesAdapter(IMAGES_LIST, imageHandlerThread)
override fun onCreateView(
inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?
): View {
imageHandlerThread.start()
_binding = FragmentHandlerThreadBinding.inflate(inflater, container, false)
return binding.root
}
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
binding.rvImages.adapter = imagesAdapter
super.onViewCreated(view, savedInstanceState)
}
override fun onDestroyView() {
super.onDestroyView()
imageHandlerThread.clearQueue()
imageHandlerThread.quit()
_binding = null
}
companion object {
val IMAGES_LIST = listOf(
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTFJFlv82Ka95K2YdwY-ysJJWu2S7BanGhVXw&s",
"https://bestfriends.org/sites/default/files/2023-04/JerryArlyneBenFrechette2915sak.jpg",
"https://www.cats.org.uk/media/12883/210908ncac104.jpg?width=500&height=333.30078125",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR4ZBVltbIEEDTKwVGA2fRX3wW7rT4tR3k_Kw&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTcPrFmN5loBnmv5CEWJ6PtBzhrAekTRh7w0Q&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT7r0kCHWP3ZrXtB8U8sfTWoE3YXy__m4_nzg&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQX63kZF6VlsxTiLH5cBYFMn00zBd-2x7OsbQ&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT5H3p6Ir1LHathVgxS96fQbXK0-twVSNdFwQ&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTIs-9IrXb1_0htSOE1hUcONujC0CoFeVOctg&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTd3FsMmvPJ3IcUOgDrBCMvsJYcSo9UeUbpMQ&s",
"https://image.petmd.com/files/petmd-kitten-facts.jpg",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQBi2UnpivXXhTW6uKH2R67lryUl3j2WklzOw&s"
)
}
} Для примера взяли несколько случайных картинок из интернета, и вот какой результат получился.

Также в профайлере можно отследить, в какой момент времени проходила обработка сообщений в потоке Images Handler Thread.
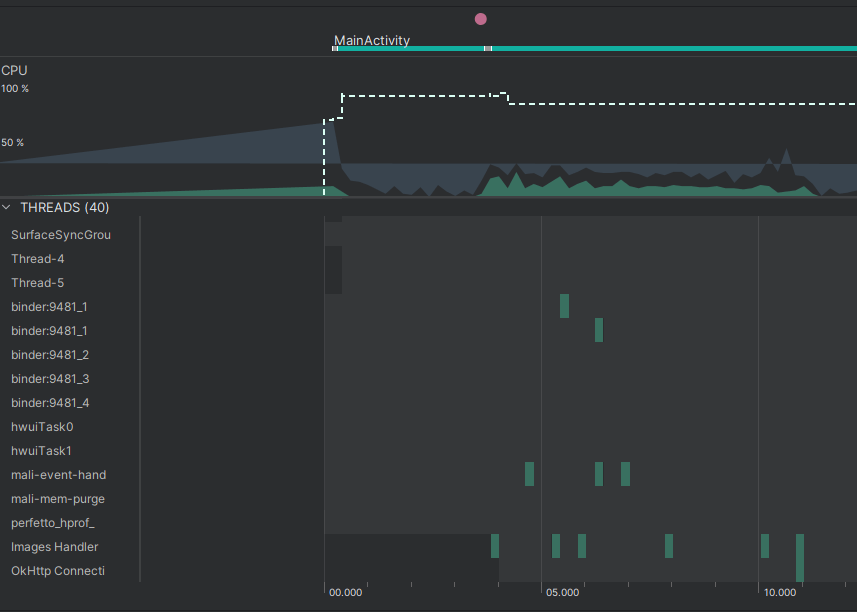
Таким образом, добавив некоторое количество шаблонного кода и чуть-чуть логики для загрузки изображений, мы реализовали загрузку списка в фоновом потоке, не нагружая при этом главный. Однако загрузку списка можно ещё оптимизировать, если загружать каждый элемент параллельно друг с другом, не дожидаясь, пока будут обработаны предыдущие. О том, как это можно сделать, мы поговорим далее.
Основное применение HandlerThread заключается в последовательном выполнении задач в фоновом режиме. Например, с его помощью можно поочерёдно выполнить несколько запросов к сети или файловой системе, или объединить несколько различных задач в цепочку.
Однако HandlerThread, как же и Thread, требует написания большого количества кода, что делает его не очень удобным для выполнения сложных операций.
AsyncTask
При рассмотрении предыдущих инструментов можно было заметить, что все они не содержат в себе никаких инструментов для взаимодействия с UI-потоком. Чтобы вернуть результат выполнения операции или прогресс выполнения, нам приходится писать дополнительный код и использовать обработчики для передачи сообщений между потоками. Поэтому в Android появился класс, называемый AsyncTask, который был призван упростить эту задачу.
Важно! Класс AsyncTask отмечен как Deprecated начиная с Android 11 (API 30). В настоящее время Google настоятельно не рекомендует его использовать, поскольку его поведение различно на разных версиях Android. Также при использовании AsyncTask высока вероятность утечки контекста и пропуска обратных вызовов, что может приводить к нестабильной работе приложения. В данной статье класс рассматривается как часть исторического развития и не рекомендуется к применению на реальных проектах.
Класс AsyncTask является обёрткой над Thread и Handler и представляет собой абстрактный обобщённый (Generic) класс, который принимает 3 параметра:
- Params — входные данные для выполнения задачи.
- Progress — Промежуточные данные для обновления прогресса выполнения.
- Result — выходные данные с результатом работы.
public abstract class AsyncTask<Params, Progress, Result>Примечание: Generic-классами в Java называются такие классы, в которых тип данных, с которыми они работают, указан в виде параметра. Это позволяет классу работать с данными независимо от того, какого типа они будут, и писать обобщённый код. Самым частым примером использования обобщённых классов в Android являются коллекции (List<T>, HashMap<K, V> и т.д.).
Поскольку AsyncTask это абстрактный класс, то при работе с ним нам необходимо создавать свой класс, который будет наследовать его.
AsyncTask предоставляет для работы с задачей 4 переопределяемых метода:
- onPreExecute() — Необязательный метод, выполняющий код, который нужно вызвать перед запуском потока. По умолчанию пустой. Код в этом методе нужно выполнять только на главном потоке.
- doInBackground(Params…) — Обязательный метод, который содержит основную логику работы нашего потока. Вызывается после выполнения onPreExecuted(). Код в нём выполняется непосредственно в фоновом потоке.
- onProgressUpdate(Progress…) — Необязательный метод, который получает данные для обновления прогресса и обрабатывает их. Выполняется только в случае, если во время работы был вызван специальный метод AsyncTask.publishProgress(Progress). По умолчанию пустой. Код в этом методе выполняется на главном потоке.
- onPostExecute(Result) — Необязательный метод, который получает результат выполнения задачи и обрабатывает его. Вызывается после завершения doInBackground(). По умолчанию пустой. Код в нём выполняется на главном потоке.
Таким образом, минимальная реализация класса будет выглядеть следующим образом:
class MyAsyncTask : AsyncTask<Void, Void, Void>() {
override fun doInBackground(vararg values: Void?): Void? {
// Код
return null
}
}Благодаря этим методам AsyncTask предоставляет удобный интерфейс, разграничивающий то, что должно быть выполнено в фоновом потоке, и то, что нужно выполнить для обновления в главном потоке.
Также AsyncTask берёт на себя создание потока, избавляя разработчика от его инициализации и настройки. Если посмотреть исходный код класса, то можно увидеть, что работа с потоками реализована с помощью Executor, который представляет собой особый механизм для управления несколькими потоками, подробнее мы рассмотрим его далее в статье.
Для передачи сообщений в главный поток используется уже знакомый нам Handler. Например, вот так выглядит метод, передающий прогресс выполнения операции из потока в UI.
@WorkerThread
protected final void publishProgress(Progress... values) {
if (!isCancelled()) {
getHandler().obtainMessage(MESSAGE_POST_PROGRESS,
new AsyncTaskResult<Progress>(this, values)).sendToTarget();
}
}Отменить AsyncTask можно с помощью метода AsyncTask.cancel(Boolean). Однако этот метод не остановит поток сию же секунду. Если в параметры передать false, то поток остановится. когда закончит вычисления. Если true — AsyncTask постарается прервать работающие потоки, но это не гарантирует моментальное завершение, поскольку существуют различные операции, которые прервать нельзя и нужно дождаться их выполнения. Поэтому основной целью метода является изменение внутри класса флага mCancelled на true, который запретит возвращение результата работы в главный поток.
Чтобы запустить AsyncTask на выполнение, нужно вызвать метод AsyncTask.execute(Params…) или AsyncTask.executeOnExecutor(Executor, Params…).
Первый метод принимает входные данные и запускает поток на Executor по умолчанию. С появлением новых версий Android реализация этого метода постоянно изменялась: в одно время запускался один фоновый поток, в другое пул из нескольких потоков. В настоящее время метод запускает код на одном отдельном потоке.
Второй метод, помимо входных данных, принимает также Executor, на котором и будет запускаться. В данном случае мы сами можем сконфигурировать Executor как нам будет удобно и не использовать вариант по умолчанию.
Напишем простой AsyncTask, который будет в цикле ждать какое-то время и отправлять обновления прогресса.
class MyAsyncTask : AsyncTask<Void, Int, Int>() {
override fun onPreExecute() {
Toast.makeText(requireContext(), "Task started", Toast.LENGTH_SHORT).show()
}
override fun doInBackground(vararg values: Void?): Int {
for (i in 1 until 10) {
publishProgress(i)
Thread.sleep(1000L)
}
return 10
}
override fun onProgressUpdate(vararg values: Int?) {
val value = values[0]
if (value != null) {
binding.progress.setProgress(value)
}
}
override fun onPostExecute(result: Int) {
Toast.makeText(requireContext(), "Task completed", Toast.LENGTH_SHORT).show()
binding.progress.setProgress(result)
}
}
val asyncTask = MyAsyncTask()
asyncTask.execute()Запустим приложение и увидим, как AsyncTask будет обновлять UI.

Код, написанный с помощью AsyncTask, выглядит лаконичнее, поскольку мы больше не заботимся о контроле потоков и может сосредоточиться непосредственно на выполнении задачи.
В предыдущей главе мы написали пример, используй HandlerThread для загрузки изображений в списке. Попробуем теперь реализовать то же самое, то на примере AsyncTask.
Создадим новый класс и назовём его ImageAsyncTask.
class ImageAsyncTask(
private val taskListener: TaskListener
) : AsyncTask<String, Int, Bitmap>() {
interface TaskListener {
fun onTaskStarted()
fun onProgressUpdated(progress: Int)
fun onTaskCompleted(bitmap: Bitmap?)
}
override fun onPreExecute() {
taskListener.onTaskStarted()
}
override fun doInBackground(vararg strings: String): Bitmap? {
publishProgress(0)
val bitmap = loadImage(strings[0])
publishProgress(100)
return bitmap
}
override fun onProgressUpdate(vararg values: Int?) {
if (values.isEmpty()) return
val progress = values[0]
if (progress != null) {
taskListener.onProgressUpdated(progress)
}
}
override fun onPostExecute(result: Bitmap?) {
taskListener.onTaskCompleted(result)
}
@WorkerThread
private fun loadImage(link: String): Bitmap? {
val url = URL(link)
var connection: HttpURLConnection? = null
var inputStream: BufferedInputStream? = null
val buffer = ByteArrayOutputStream()
return try {
connection = url.openConnection() as HttpURLConnection
connection.connect()
inputStream = BufferedInputStream(connection.inputStream)
val totalSize = connection.contentLength
val bufferSize = 512
val tempBuffer = ByteArray(bufferSize)
var bytesRead: Int
var downloadedSize: Int = 0
while (inputStream.read(tempBuffer, 0, bufferSize).also { bytesRead = it } != -1) {
buffer.write(tempBuffer, 0, bytesRead)
downloadedSize += bytesRead
if (totalSize > 0) {
publishProgress((downloadedSize * 100) / totalSize)
}
}
val array = buffer.toByteArray()
BitmapFactory.decodeByteArray(array, 0, array.size)
} catch (e: IOException) {
null
} finally {
connection?.disconnect()
inputStream?.close()
buffer.flush()
buffer.close()
}
}
}В качестве входных данных будет использоваться ссылка на изображение, на выходе мы получаем готовый Bitmap, а промежуточные данные — прогресс загрузки изображения. Логика загрузки изображения аналогична предыдущей реализации за исключением того, что был добавлен подсчёт загруженных данных для вычисления прогресса загрузки. Также мы добавили интерфейс для обратных вызовов в адаптер со списком.
Аналогично напишем адаптер для нашего списка. Этот адаптер будет слегка отличаться от варианта с HandlerThread, мы будет создавать AsyncTask каждый раз при инициализации ячейки списка.
class ImageAsyncTaskAdapter(
private val images: List,
) : RecyclerView.Adapter() {
override fun getItemCount(): Int = images.count()
override fun onCreateViewHolder(
parent: ViewGroup,
viewType: Int
) = ImageHolder(
ItemImageBinding.inflate(
LayoutInflater.from(parent.context),
parent,
false
)
)
override fun onBindViewHolder(
holder: ImageHolder,
position: Int
) = holder.bind(images[position])
class ImageHolder(
private val binding: ItemImageBinding
) : RecyclerView.ViewHolder(
binding.root
) {
fun bind(image: String) {
binding.progressLoading.isIndeterminate = false
binding.progressLoading.max = 100
val asyncTask = ImageAsyncTask(object : ImageAsyncTask.TaskListener {
override fun onTaskStarted() {
showProgress()
}
override fun onProgressUpdated(progress: Int) {
binding.progressLoading.progress = progress
}
override fun onTaskCompleted(bitmap: Bitmap?) {
hideProgress()
binding.ivImage.setImageBitmap(bitmap)
}
})
asyncTask.execute(image)
}
private fun showProgress() {
binding.ivImage.visibility = View.INVISIBLE
binding.progressLoading.visibility = View.VISIBLE
}
private fun hideProgress() {
binding.ivImage.visibility = View.VISIBLE
binding.progressLoading.visibility = View.GONE
}
}
} Всё, что осталось сделать, это добавить новый фрагмент, добавить на него RecyclerView и установить адаптер.
class ImageAsyncTaskFragment : Fragment() {
private var _binding: FragmentImageAsyncTaskBinding? = null
// This property is only valid between onCreateView and
// onDestroyView.
private val binding get() = _binding!!
private val imagesAdapter: ImageAsyncTaskAdapter = ImageAsyncTaskAdapter(IMAGES_LIST)
override fun onCreateView(
inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?
): View {
_binding = FragmentImageAsyncTaskBinding.inflate(inflater, container, false)
return binding.root
}
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
binding.rvImages.adapter = imagesAdapter
super.onViewCreated(view, savedInstanceState)
}
override fun onDestroyView() {
super.onDestroyView()
_binding = null
}
private companion object {
val IMAGES_LIST = listOf(
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTFJFlv82Ka95K2YdwY-ysJJWu2S7BanGhVXw&s",
"https://bestfriends.org/sites/default/files/2023-04/JerryArlyneBenFrechette2915sak.jpg",
"https://www.cats.org.uk/media/12883/210908ncac104.jpg?width=500&height=333.30078125",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR4ZBVltbIEEDTKwVGA2fRX3wW7rT4tR3k_Kw&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTcPrFmN5loBnmv5CEWJ6PtBzhrAekTRh7w0Q&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT7r0kCHWP3ZrXtB8U8sfTWoE3YXy__m4_nzg&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQX63kZF6VlsxTiLH5cBYFMn00zBd-2x7OsbQ&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT5H3p6Ir1LHathVgxS96fQbXK0-twVSNdFwQ&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTIs-9IrXb1_0htSOE1hUcONujC0CoFeVOctg&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTd3FsMmvPJ3IcUOgDrBCMvsJYcSo9UeUbpMQ&s",
"https://image.petmd.com/files/petmd-kitten-facts.jpg",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQBi2UnpivXXhTW6uKH2R67lryUl3j2WklzOw&s"
)
}
}Запустим приложение и посмотрим результат.

Однако наши изображения до сих пор загружаются последовательно друг за другом, а не параллельно. Это объясняется тем, что мы запускаем AsyncTask через метод AsyncTask.execute(). В этом случае AsyncTask использует свой Executor по умолчанию, который последовательно обрабатывает поступающие задачи в отдельном потоке. Поэтому, хоть мы и запустили сразу несколько AsyncTask, они будут выполняться один за другим в том порядке, в каком попадут в очередь.
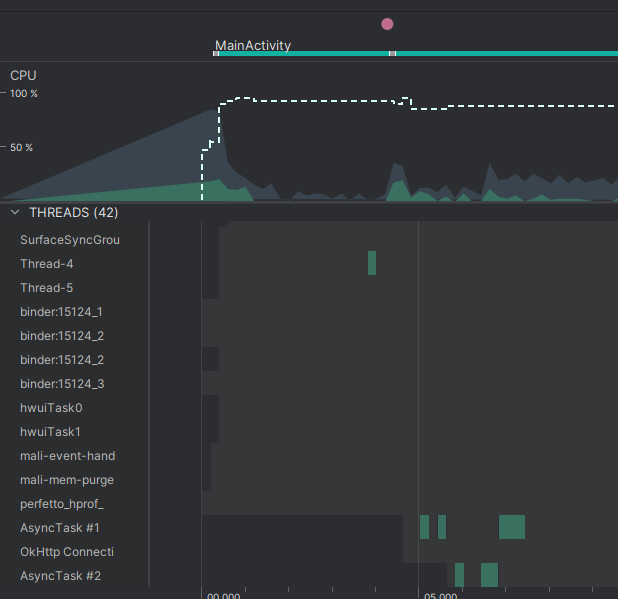
Попробуем сделать загрузку изображений параллельной. Для этого в адаптере объявим свой Executor и будем передавать его в AsyncTask.executeOnExecutor().
class ImageAsyncTaskAdapter(
private val images: List,
) : RecyclerView.Adapter() {
// Создаём новый Executor с количеством потоков, равным 5
private val executor = Executors.newFixedThreadPool(5)
override fun getItemCount(): Int = images.count()
override fun onCreateViewHolder(
parent: ViewGroup,
viewType: Int
) = ImageHolder(
ItemImageBinding.inflate(
LayoutInflater.from(parent.context),
parent,
false
)
)
override fun onBindViewHolder(
holder: ImageHolder,
position: Int
) = holder.bind(images[position], executor)
class ImageHolder(
private val binding: ItemImageBinding
) : RecyclerView.ViewHolder(
binding.root
) {
fun bind(image: String, executor: ExecutorService) {
binding.progressLoading.isIndeterminate = false
binding.progressLoading.max = 100
val asyncTask = ImageAsyncTask(object : ImageAsyncTask.TaskListener {
override fun onTaskStarted() {
showProgress()
}
override fun onProgressUpdated(progress: Int) {
binding.progressLoading.progress = progress
}
override fun onTaskCompleted(bitmap: Bitmap?) {
hideProgress()
binding.ivImage.setImageBitmap(bitmap)
}
})
// Передаём наш Executor в AsyncTask
asyncTask.executeOnExecutor(executor, image)
}
private fun showProgress() {
binding.ivImage.visibility = View.INVISIBLE
binding.progressLoading.visibility = View.VISIBLE
}
private fun hideProgress() {
binding.ivImage.visibility = View.VISIBLE
binding.progressLoading.visibility = View.GONE
}
}
} Посмотрим, что изменилось.

Загрузка изображений заметно ускорилась за счёт использования одновременно пяти потоков, каждый из которых загружает своё изображение.
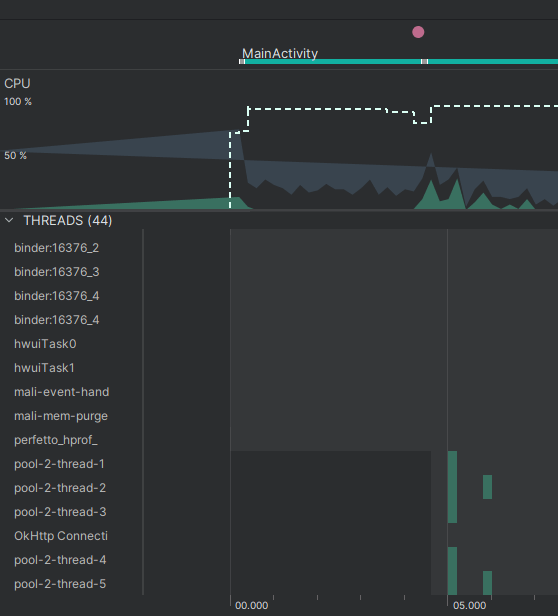
AsyncTask отлично подходил для выполнения несложных кратковременных операций в потоке. Для длительной работы всё же рекомендовалось использовать Thread, которые дают больше возможностей для контроля над потоками.
Долгое время AsyncTask являлся одним из часто используемых классов для работы с многопоточностью. Однако, не смотря на его достоинства и простоту в работе, в итоге от AsyncTask пришлось отказаться, так как его недостатки были весьма существенны.
Отмена задачи по сути лишь исключала доставку результата в UI-поток, но не останавливала выполнение работы в потоке.
Если запущенной активности нужно было изменить конфигурацию (при смене языка, при повороте экрана и т.п.), но ссылка на запущенный AsyncTask терялась и, как следствие, результат её работы, и приходилось запускать задачу заново.
Из вышеописанной проблемы также вытекает следующая: если повернуть экран и пересоздать активность, то также будет создан и новый UI-поток. А поскольку запущенный поток в AsyncTask хранит ссылку на предыдущий экземпляр UI-потока, то сборщик мусора не сможет удалить его и освободить память в системе. Всё это приводит к утечкам памяти, когда в системе выделена память на уже не используемые объекты, что негативно сказывается не только на работе приложения, но и самого устройства. Частично эту проблему можно решить, используя слабые ссылки на объекты (WeakReference), но это приведёт к написанию дополнительного шаблонного кода, которого хотелось бы избежать.
Всё это вместе привело к тому, что в Android решили отказаться использовать AsyncTask, что заставило изучать другие альтернативы.
Loader и LoaderManager
Позднее в Android также появился ещё один класс, помогающий решать задачу разгрузки главного потока и обновления UI из других потоков, — Loader.
Важно! Класс Loader отмечен как Deprecated начиная с Android 9 (API 28). В настоящее время этот класс практически не используется, поскольку его задачи сейчас решают более современные ViewModel и LiveData. Однако если есть необходимость в использовании Loader, то в библиотеке поддержки есть специальная зависимость androidx.loader:loader для использования на современных версиях Android.
Класс Loader предоставляет возможность загружать данные из поставщика контента или другого источника для отображения в FragmentActivity или Fragment.
К основным достоинствам Loader можно отнести следующее:
- Запускаются на отдельных потоках для предотвращения замедления UI-потока.
- Упрощают управление потоками, предоставляя методы обратного вызова при срабатывании событий.
- Сохраняют и кешируют результат работы при изменении конфигурации для предотвращения повторных запросов.
- Могут реализовывать наблюдатель для мониторинга изменений в источнике данных. Например, CursorLoader автоматически регистрирует ContentObserver, который запускает перезагрузку при изменении данных.
Помимо Loader, есть ещё два ключевых класса:
- LoaderManager
- LoaderManager.LoaderCallback
LoaderManager — абстрактный класс, связанный с FragmentActivity или Fragment для управление экземплярами Loader. Для каждой активности или фрагмента существует только один экземпляр LoaderManager. Чтобы получить доступ к LoaderManager, можно воспользоваться функцией FragmentActivity.getSupportLoaderManager().
Для того, чтобы загрузить данные из Loader, можно воспользоваться методами LoaderManager.initLoader(Int, Bundle, LoaderManager.LoaderCallback) или LoaderManager.restartLoader(Int, Bundle, LoaderManager.LoaderCallback). Система автоматически определит, существует ли Loader с указанным идентификатором, и либо создаст новый, либо перезапустит существующий.
Интерфейс LoaderManager.LoaderCallback реализовывают активности или фрагменты, которые собираются получать результат методов обратного вызова от событий в загрузчиках. Он включает в себя такие методы, как onCreateLoader(Int, Bundle), onLoadFinished(Loader, Result) и onLoaderReset(Loader).
Метод onCreateLoader(Int, Bundle) возвращает новый экземпляр загрузчика, который был создан с помощью метода LoaderManager.initLoader(Int, Bundle, LoaderManager.LoaderCallback).
Метод onLoadFinished(Loader, Result) вызывается, когда загрузки выполнил свою работу и возвращает результат в главный поток.
Метод onLoaderReset(Loader) сообщает о том, что загрузчик собирается перезапуститься из-за изменения данных. В этом случае можно сохранить данные до того, как они сбросятся.
Поскольку LoaderManager связан с FragmentActivity, он знает об её жизненном цикле и при уничтожении активности закрывает все работающие загрузчики для экономии ресурсов, чего не умеет AsyncTask из предыдущей главы.
LoaderManager работает с обобщённым классом Loader<T>, где T может быть любым типом, в который будут загружены данные.
Класс Loader является абстрактным, поэтому для работы с ним нужно создавать собственный класс, наследующий от него. Однако в Android есть два готовых класса CursorLoader и AsyncTaskLoader, которые избавляют от необходимости писать собственный загрузчик.
AsyncTaskLoader<D> представляет собой абстрактный класс, принимающий в качестве параметра тип данных, в который необходимо загрузить результат работы. Этот класс реализует внутри себя часть функционала AsyncTask, реализовывая работу загрузчика в отдельном потоке. Для того, чтобы с ним работать, нужно создать класс, наследующий от AsyncTaskLoader, и переопределить метод AsyncTaskLoader.loadInBackground(), код внутри которого выполняется в отдельном потоке.
CursorLoader является частным случаем AsyncTaskLoader. Данный класс наследует от AsyncTaskLoader<Cursor> и предназначен для заполнения курсора данными из провайдера контента.
Рассмотрим небольшой пример. У нас есть база данных SQLite, которая содержит в себе одну таблицу с двумя полями “_id” и “message”. Попробуем извлечь все записи из поля “message” и отобразить их на экране.
Для этого создадим свой класс MyCustomLoader, наследующий от AsyncTaskLoader<String>. В методе loadInBackground() добавим некоторую задержку и вернём результат запроса к базе данных.
private class MyCustomLoader(
context: Context
) : AsyncTaskLoader(context) {
override fun loadInBackground(): String {
val db = TestDatabase(context)
db.open()
Thread.sleep(3000)
val cursor = db.getAllData()
val sb = StringBuilder().apply {
if (cursor != null && cursor.count > 0) {
while (cursor.moveToNext()) {
val columnIndex = cursor.getColumnIndex(TestDatabase.COLUMN_TXT)
append(cursor.getString(columnIndex))
append("\n")
}
}
}
db.close()
return sb.toString()
}
} Инициализируем наш загрузчик.
requireActivity().supportLoaderManager.initLoader(LOADER_ID, null, this).forceLoad()Реализуем интерфейс LoaderManager.LoaderCallback<String>, который будет получать результат выполнения.
class SimpleLoaderFragment : Fragment(), LoaderManager.LoaderCallbacks<String>В методе onCreateLoader(Int, Bundle) мы будем возвращать новый экземпляр класса MyCursorLoader.
override fun onCreateLoader(id: Int, args: Bundle?): Loader<String> {
return MyCustomLoader(requireContext())
}Метод onLoaderReset(Loader) оставим пустым, т.к. в данном примере он не нужен.
В методе onLoadFinished(Loader, String) получим строку, заполненную данными из курсора, после чего отобразим в UI.
override fun onLoadFinished(loader: Loader<String>, data: String) {
binding.result.text = data
}Как результат, сообщения из нашей базы данных успешно загрузились.
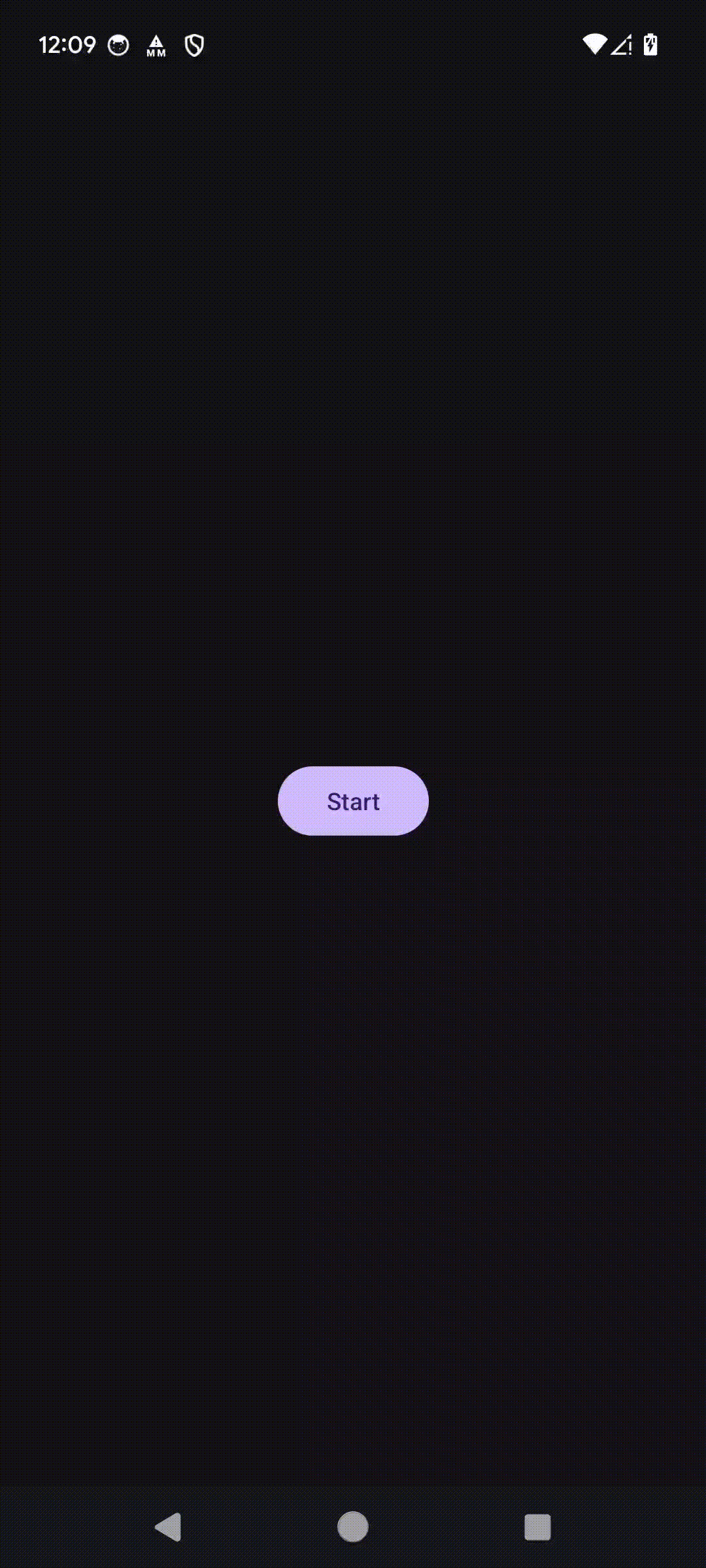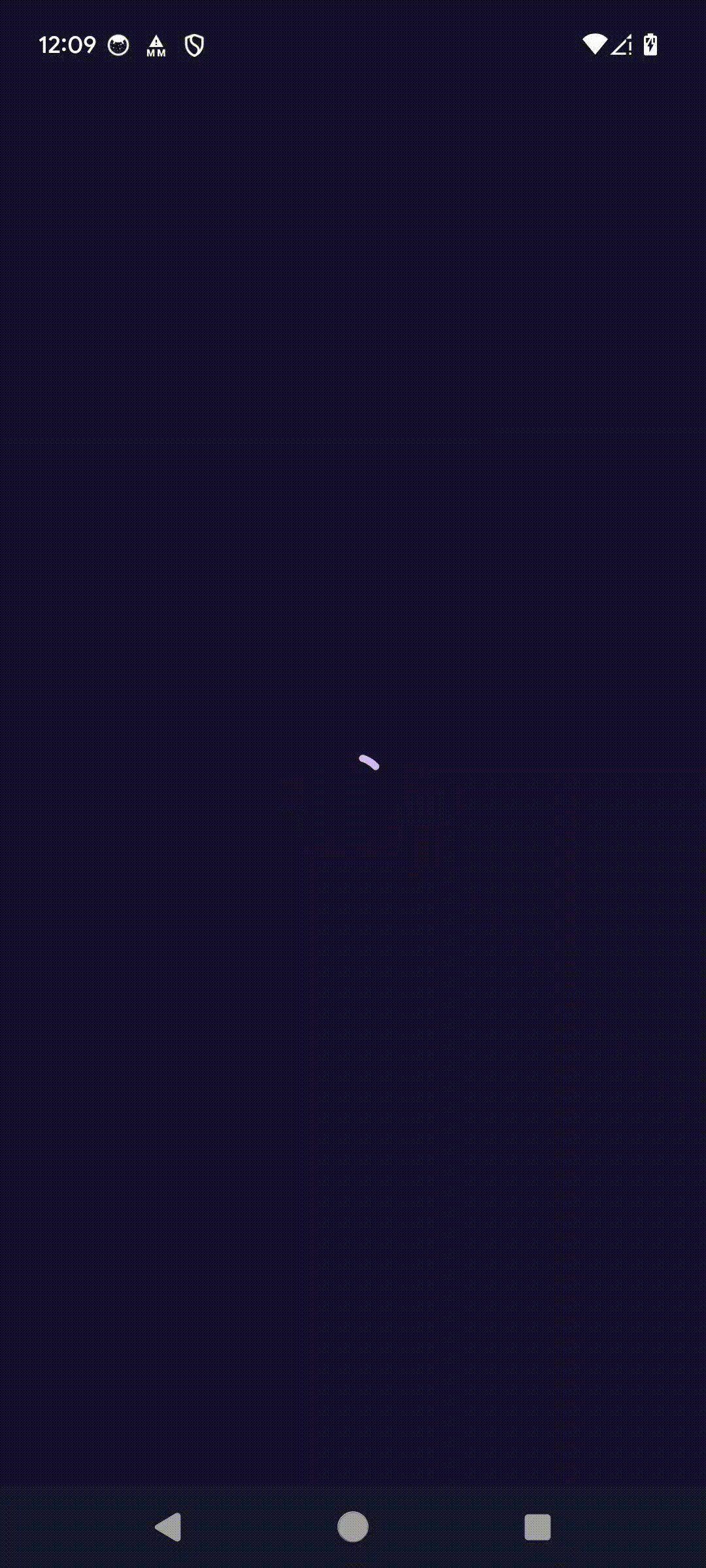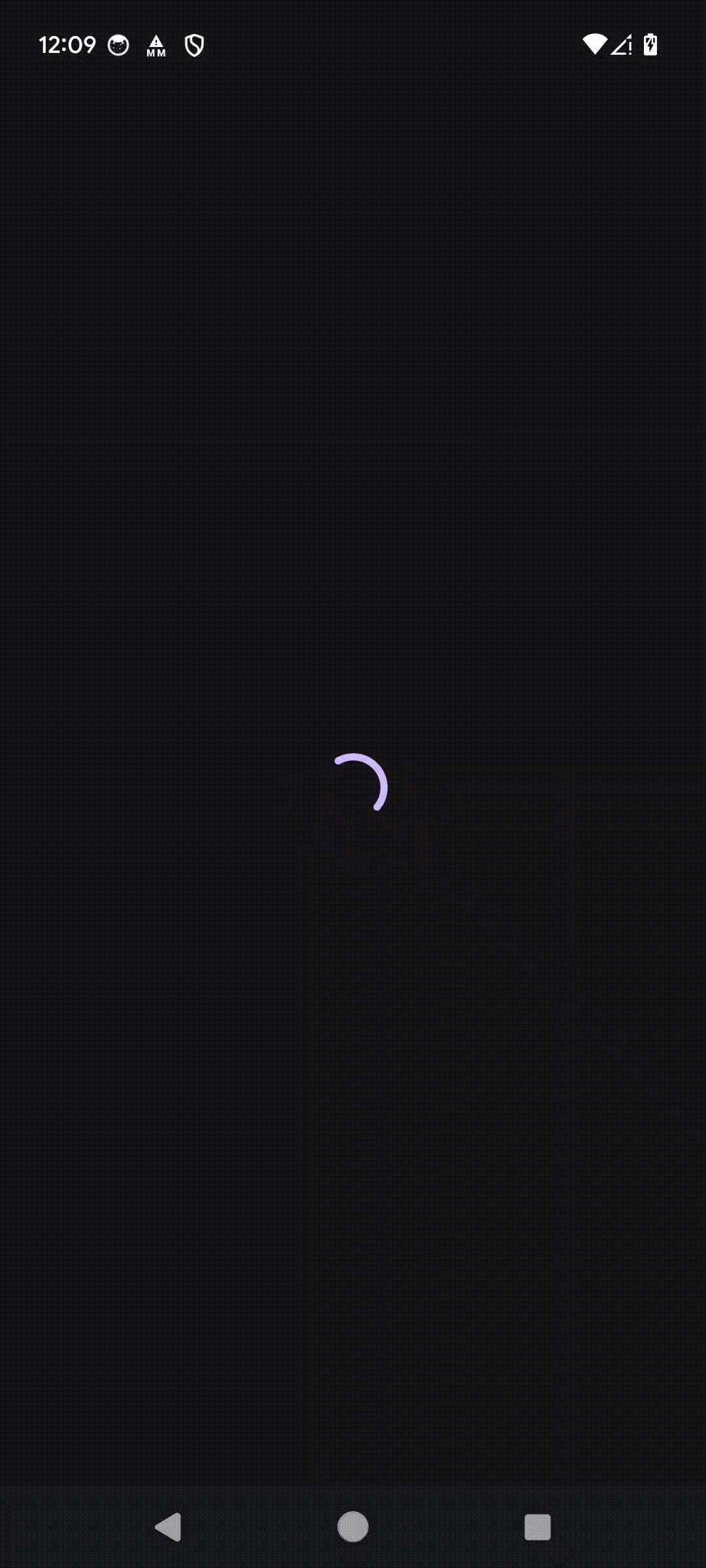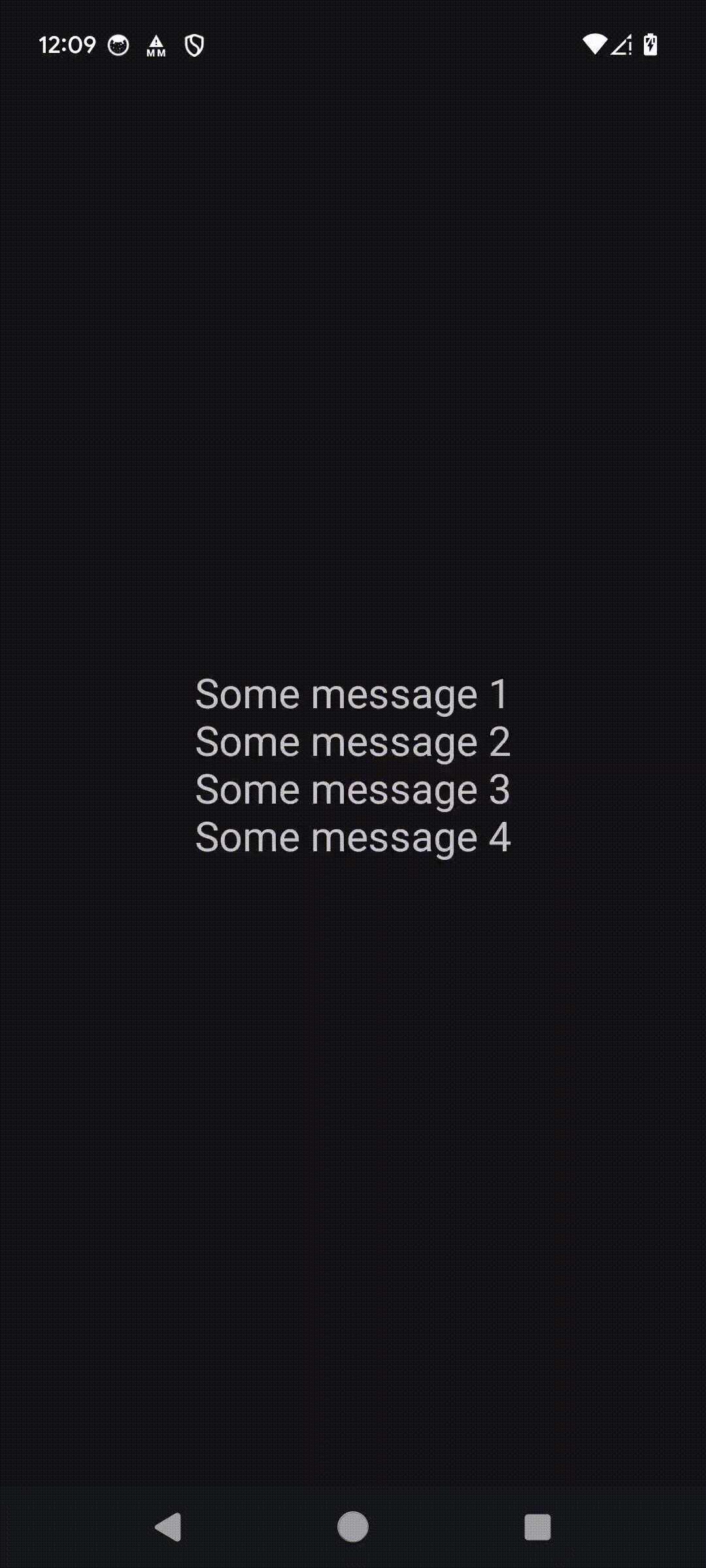
Благодаря встроенному AsyncTask UI на время выполнения не зависает и мы можем продолжить работу с приложением.
Большим преимуществом Loader над AsyncTask является сохранение данных при изменении конфигурации. Если мы, к примеру, повернём экран во время загрузки, то LoaderManager просто заново присоединится к новому экземпляру активности/фрагмента, сохраняя при этом информацию о загрузчиках. Поэтому повторный вызов initLoader() вернёт уже существующий загрузчик, который в свою очередь уже выполнил работу и хранит результат.
К недостаткам можно отнести отсутствие механизмов для обновления прогресса, однако это можно реализовать своими средствами.
Executor
До сих пор мы работали с одним-двумя потоками. Однако в крупных проектах таких потоков может быть большое количество. Создание каждого нового Thread это дорогостоящая операция, под которую выделяются значительные объёмы памяти. При неправильном использовании это может привести к нехватке памяти и ухудшению работы приложения. С целью оптимизации управления потоками в Android существует механизм Executor. Мы уже видели его раньше, когда изучали AsyncTask, теперь рассмотрим подробнее.
Фреймворк Executor предоставляет несколько компонентов, благодаря которым можно создавать и управлять сразу несколькими потоками. Он умеет заново использовать уже отработавшие потоки, что позволяет уменьшить потребляемую память.
Ключевыми здесь являются 3 интерфейса:
- Executor — содержит всего один метод execute(Runnable), который запускает задачу с заданным Runnable.
- ExecutorService — наследует от Executor и добавляет методы для управления жизненным циклом потоков. Также предоставляет метод submit(), который похож на execute(), но предоставляет больше возможностей для запуска задач и возвращает объект Future, использующийся для возвращения результата выполнения.
- ScheduledExecutorService — наследует от ExecutorService и добавляет методы, реализовывающие планирование запуска задачи.
Также важным является вспомогательный класс Executors. Он содержит в себе методы по созданию ExecutorService и ScheduledExecutorService с базовыми вариантами конфигурации.
Все вместе они служат для создания пула потоков. Пул потоков (ThreadPool) представляет собой какое-то заданное число работающих вместе потоков, которые обрабатывают поступающую очередь из Runnable. Как только задача попадает в очередь, её забирает один из свободных потоков и выполняет, после чего ожидает новые задачи.
Чтобы отправить Runnable в пул потоков, вызывается уже упомянутый выше метод Executor.execute() либо ExecutorService.submit().
Чтобы остановить пул потоков, нужно вызвать метод ExecutorService.shutdown() или ExecutorService.shutdownNow(). Первый метод дожидается выполнения всех задач в очереди и останавливает пул, второй запрещает задачам в очереди запускаться и пытается остановить текущие задачи.
Рассмотрим основные конфигурации пула потоков, которые предоставляет класс Executors.
- newSingleThreadExecutor()
Как следует из названия, создаёт пул, содержащий один поток. Поэтому в один момент времени может выполнять только одну задачу, все остальные задачи ожидают в очереди.
- newFixedThreadPool()
Создаёт пул, содержащий фиксированное число потоков. Мы можем задать нужное количество, передав его в параметры метода. newSingleThreadExecutor() является частным случаем newFixedThreadPool() и эквивалентен вызову newFixedTheadPool(1). К примеру, если мы создадим пул из 4 потоков, а задач у нас будет 10, то в один момент времени будут выполняться 4 задачи, а остальные 6 — находиться в очереди ожидания. Как только один из потоков освободится, он сразу возьмёт на выполнение следующую задачу из очереди.
- newCachedThreadPool()
Создаёт пул с динамически меняющимся количеством потоков. Максимальный размер такого пула равен максимальному целочисленному значению в Java. Сконфигурированный таким образом пул создаёт новые потоки по необходимости и уничтожает свободные потоки, если те бездействуют дольше минуты. Таким образом, если на выполнение поступит 10 задач, то пул создаст 10 потоков, которые отработают, а затем будут уничтожены из-за простоя.
Таким образом, если нам нужно ограничить количество одновременно выполняемых задач, то следует использовать newSingleThreadExecutor() или newFixedThreadPool(). Если же требуется максимально ускорить работу, то отлично подойдёт newCachedThreadPool().
Что касается создания ScheduledExecutorService, то тут тоже есть несколько стандартных вариантов.
- newSingleThreadScheduledExecutor()
Аналогичен newSingleThreadExecutor(), но позволяет запускать задачи не сразу, а с определённой задержкой или после через регулярные промежутки времени.
- newScheduledThreadPool()
Аналогичен newFixedThreadPool(). Создаёт пул из заданного количества потоков. Вызов newSingleThreadScheduledExecutor() эквивалентен newSchedulerThreadPool(1).
Для запуска ScheduledExecutorService используются три метода:
- schedule(Runnable, Long, TimeUnit) — запускает выполнение после заданной задержки, принимает в параметрах задачу, время задержки и единицы измерения времени.
- scheduleAtFixedRate(Runnable, Long, Long, TimeUnit) — запускает выполнение после заданной задержки и затем регулярного промежутка времени.
- scheduleWithFixedDelay(Runnable, Long, Long, TimeUnit) — запускает выполнение после заданной начальной задержки и затем после последующей задержки.
Кроме того, в Android 7.0 (API 24) появилась возможность создания ещё одного пула потоков: Executors.newWorkStealingPool().
Данный пул потоков отличается от предыдущих тем, что работает по принципу “кражи” работы, когда один процессор может украсть задачу у другого, если тот занят.
В параметры ему можно передать желаемый уровень параллелизма, который будет соответствовать максимальному числу потоков. Фактическое же число потоков может динамически изменяться по ходу работу. Если не передавать ничего, то уровень параллелизма будет выставлен в соответствии с количеством ядер процессора, доступных виртуальной машине Java.
Из-за того, что потоки могут выполнять задачи хаотически, данный пул потоков не гарантирует последовательный порядок в выполнении задач.
Мы разобрались с тем, какие бывают стандартные конфигурации пулов. Однако мы также можем создать и свой собственный.
Если заглянуть в исходники выше перечисленных методов, то можно обнаружить, что все они используют для создания класс ThreadPoolExecutor. Исключением является только newWorkStealingPool(), который создаёт экземпляр класса ForkJoinPool.
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}Класс ThreadPoolExecutor реализовывает интерфейсы Executor и ExecutorService и отвечает за создание потоков и выполнение в них задач. Он имеет 4 конструктора, в которые мы можем передать следующие параметры:
- corePoolSize — количество потоков, которые будут запущены при старте.
- maximumPoolSize — максимальное количество потоков, которое можно создать.
- keepAliveTime — время, в течение которого поток может жить.
- unit — единицы измерения времени для параметра keepAliveTime.
- workQueue — очередь для хранения задач.
- handler — обработчик задач, которые не могут быть выполнены.
- threadFactory — объект, создающий новые потоки по требованию.
Определив все эти параметры, можно создавать ThreadPoolExecutor любой нужной конфигурации. В случае, если нам нужно добавить планировщик выполнения, то вместо ThreadPoolExecutor нужно создавать ScheduledThreadPoolExecutor, который от него наследует.
Однако создание собственных пулов является нетривиальных задачей и представленные в классе Executors конфигурации покрываются подходят для самых распространённых сценариев работы.
Напишем небольшой пример. Как и раньше, попробуем загрузить изображения для списка в RecyclerView, но с помощью ThreadPoolExecutor.
Для начала создадим класс, наследующий от Runnable, в котором будет находиться логика загрузки изображения, знакомая нам по предыдущим примерам. Также сюда мы будем передавать слабые ссылки (WeakReference) на элементы UI, которые нужно будет обновить, и ConcurrentHashMap<String, Bitmap?>, задачей которого будет кешировать загруженные изображения.
class ImageDownloadRunnable(
private val imageViewRef: WeakReference,
private val progressRef: WeakReference,
private val imageUrl: String,
private val cache: ConcurrentHashMap<String, Bitmap?>
) : Runnable {
override fun run() {
progressRef.get()?.let { progress ->
progress.post { progress.visibility = View.VISIBLE }
}
imageViewRef.get()?.let { target ->
target.post { target.visibility = View.INVISIBLE }
}
val bitmap = loadImage(imageUrl).also {
if (it != null) {
cache[imageUrl] = it
}
}
progressRef.get()?.let { progress ->
progress.post { progress.visibility = View.INVISIBLE }
}
if (bitmap != null) {
imageViewRef.get()?.let { target ->
target.post {
target.visibility = View.VISIBLE
target.setImageBitmap(bitmap)
}
}
}
}
private fun loadImage(imageUrl: String): Bitmap? {
val url = URL(imageUrl)
var connection: HttpURLConnection? = null
return try {
connection = url.openConnection() as HttpURLConnection
connection.connect()
BufferedInputStream(connection.inputStream).use { `is` ->
BitmapFactory.decodeStream(`is`)
}
} catch (e: IOException) {
null
} finally {
connection?.disconnect()
}
}
} Теперь напишем класс, который будет хранить наш пул потоков и кэш. Он и будет принимать запросы на загрузку от адаптера RecyclerView и отправлять задачи в ThreadPoolExecutor. Для того, чтобы максимального быстро загрузить список, выберем newCachedThreadPool().
class ImageDownloader {
private val executorService: ExecutorService = Executors.newCachedThreadPool()
private val cache = ConcurrentHashMap<String, Bitmap?>()
fun destroy() {
executorService.shutdown()
cache.clear()
}
fun download(
imageUrl: String,
imageView: ImageView,
progress: CircularProgressIndicator
) {
if (cache[imageUrl] != null) {
imageView.setImageBitmap(cache[imageUrl])
return
}
val imageDownloadRunnable = ImageDownloadRunnable(
WeakReference(imageView),
WeakReference(progress),
imageUrl,
cache
)
executorService.submit(imageDownloadRunnable)
}
}В адаптере RecyclerView мы будем всего лишь инициализировать новые элементы списка и отправлять из них запрос на загрузку изображений. Если же изображение уже загружено и закешировано, оно будет получено сразу же из HashMap.
class ExecutorImagesAdapter(
private val images: List,
private val imageDownloader: ImageDownloader
) : RecyclerView.Adapter() {
override fun getItemCount(): Int = images.count()
override fun onCreateViewHolder(
parent: ViewGroup,
viewType: Int
) = ImageHolder(
ItemImageBinding.inflate(
LayoutInflater.from(parent.context),
parent,
false
)
)
override fun onBindViewHolder(
holder: ImageHolder,
position: Int
) = holder.bind(images[position], imageDownloader)
class ImageHolder(
private val binding: ItemImageBinding
) : RecyclerView.ViewHolder(
binding.root
) {
fun bind(image: String, imageDownloader: ImageDownloader) =
imageDownloader.download(image, binding.ivImage, binding.progressLoading)
}
} И код фрагмента, который инициализирует адаптер и ImageDownloader выглядит следующим образом:
class ExecutorFragment : Fragment() {
private var _binding: FragmentExecutorBinding? = null
private val imageDownloader = ImageDownloader()
private val executorImagesAdapter = ExecutorImagesAdapter(IMAGES_LIST, imageDownloader)
// This property is only valid between onCreateView and
// onDestroyView.
private val binding get() = _binding!!
override fun onCreateView(
inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?
): View {
_binding = FragmentExecutorBinding.inflate(inflater, container, false)
return binding.root
}
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
binding.rvImages.adapter = executorImagesAdapter
super.onViewCreated(view, savedInstanceState)
}
override fun onDestroyView() {
super.onDestroyView()
imageDownloader.destroy()
_binding = null
}
private companion object {
val IMAGES_LIST = listOf(
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTFJFlv82Ka95K2YdwY-ysJJWu2S7BanGhVXw&s",
"https://bestfriends.org/sites/default/files/2023-04/JerryArlyneBenFrechette2915sak.jpg",
"https://www.cats.org.uk/media/12883/210908ncac104.jpg?width=500&height=333.30078125",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR4ZBVltbIEEDTKwVGA2fRX3wW7rT4tR3k_Kw&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTcPrFmN5loBnmv5CEWJ6PtBzhrAekTRh7w0Q&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT7r0kCHWP3ZrXtB8U8sfTWoE3YXy__m4_nzg&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQX63kZF6VlsxTiLH5cBYFMn00zBd-2x7OsbQ&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT5H3p6Ir1LHathVgxS96fQbXK0-twVSNdFwQ&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTIs-9IrXb1_0htSOE1hUcONujC0CoFeVOctg&s",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTd3FsMmvPJ3IcUOgDrBCMvsJYcSo9UeUbpMQ&s",
"https://image.petmd.com/files/petmd-kitten-facts.jpg",
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQBi2UnpivXXhTW6uKH2R67lryUl3j2WklzOw&s"
)
}
}Запустим приложение и посмотрим результат.

Список загрузился практически моментально! Если обратиться к профайлеру, можно увидеть, что пул выделил 9 потоков. За счёт того, что изображения имеют разный размер и соответственное время на загрузку, один из поток загрузил изображение раньше остальных и перешёл к следующему в очереди.
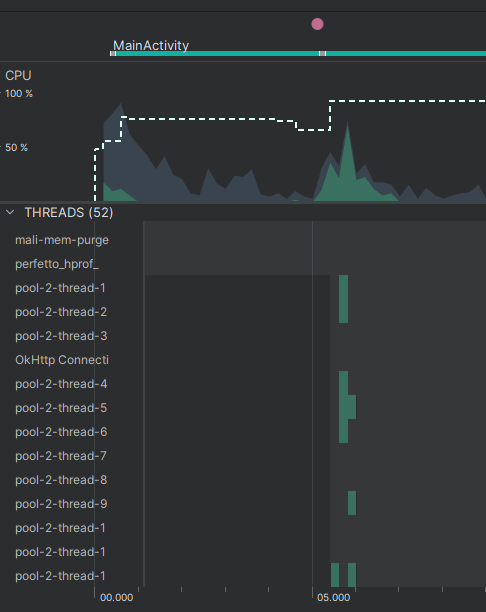
Ранее мы упоминали, что такой пул самостоятельно уничтожает потоки, если они стоят без работы дольше минуты. Это тоже можно наблюдать с помощью профайлера. На отметке 1:06 пул начал уничтожение потоков, поскольку обновлений списка и новых задач с начала запуска не было.
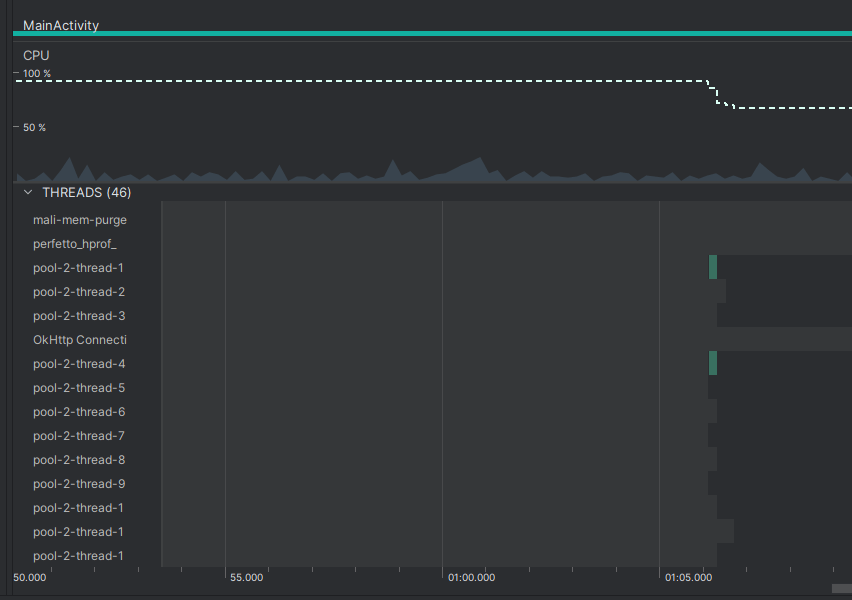
Таким образом, фреймворк Executor предоставляет широкие возможности по взаимодействию с большим количеством потоков. Переиспользование запущенных потоков, экономия памяти и управление потоками положительно сказываются на производительности и позволяют писать производительные многопоточные приложения.
RxJava
Не смотря на обилие инструментов для реализации многопоточности, долгое время самым популярным из них являлся фреймворк под названием RxJava.
RxJava представляет собой отдельную подключаемую библиотеку от ReactiveX, которая предоставляет разработчикам механизмы для написания асинхронного и реактивного кода.
Примечание: Для Android может пригодиться также библиотека RxAndroid, которая расширяет функционал RxJava, добавляя взаимодействие с главным потоком приложения.
Реактивное программирование — это способ написания программ, который позволяет им реагировать на изменение данных или событий. В основе реактивного программирования лежат создание и управление потоками данных, а также добавление наблюдателей, которые подписываются на потоки и реагируют на изменения.
В качестве “реального” примера можно привести таблицу в Excel. Допустим, в таблице описана некая формула, для которой в ячейках прописаны значения. Если изменить значение в одной из ячеек, то формула тут же перезапустит вычисления и выведет новый результат. По такому же принципу работает и реактивный код.
Основная задача библиотеки RxJava заключается как раз в том, чтобы реализовать эти принципы в JVM.
В основе фреймворка лежат два ключевых понятия: наблюдаемое и наблюдатель.
Наблюдаемое (Observable) — это поток информации, источник данных. При изменении Observable меняются и данные.
Наблюдатель (Observer) — это обработчик событий. Он наблюдает за потоком данных и выполняет нужные операции при изменении данных. Кроме того, наблюдатель сам может являться наблюдаемым для другого наблюдателя.
Observer подписывается на последовательность Observable. Последовательность посылает наблюдателю элементы по одному за раз. Наблюдатель обрабатывает каждый из них перед тем, как обработать следующий.
Благодаря этим двум компонентам RxJava может создавать цепочки операций над данным, объединять, фильтровать, преобразовывать и комбинировать последовательности. И всё это асинхронно и без блокировки главного потока.
Observer представляет собой интерфейс, который нужно реализовывать каждый раз при подписке на Observable для получения данных. Этот интерфейс включает в себя 4 метода:
- onSubscribe(Disposable) — вызывается при подписке на поток данных.
- onNext(T) — вызывается, когда происходит событие или приходят данные.
- onError(Throwable) — вызывается, когда произошла ошибка.
- onComplete() — вызывается, когда поток данных завершает свою работу и событий больше не будет.
Observable — базовый класс, который содержит в себе основную часть реализации Rx.
Observable может быть двух видов:
- Неблокирующий — асинхронное выполнение операций с возможностью отписаться от потока в любой момент.
- Блокирующий — все вызовы наблюдателя будут синхронными и отписаться в середине потока будет невозможно.
Чтобы создать Observable, нужно вызвать метод Observable.create(ObservableOnSubscribe<T>). Аргументом здесь является объект, реализующий интерфейс ObservableOnSubscribe<T>, который содержит в себе метод subcribe(ObservableEmitter<T>). Этот метод вызывается каждый раз при появлении нового подписчика.
В метод subscribe() передаётся объект, реализующий интерфейс ObservableEmitter<T>. Этот объект служит передатчиком данных и содержит методы, похожие на методы Observer:
- onNext(T) — передаёт необходимые данные наблюдателю.
- onError(T) — сообщает об ошибке.
- onComplete() — сообщает о завершении.
С помощью Observable.create() можно обернуть практически любой код и работать с ним в реактивном стиле.
Например, напишем небольшой пример. Создадим внутри Observable таймер, который будет ежесекундно посылать события с текущим временем.
Observable.create { emitter ->
Timer().apply {
schedule(object : TimerTask() {
override fun run() {
emitter.onNext(Date())
}
}, 0L, 1000L)
}
}.subscribe { date -> Log.d(TAG, "Current time: $date") }Если посмотрим в LogCat, то увидим, как каждую секунду у нас обновляются логи после того, как эмиттер отправит сообщение.

Также в RxJava есть другие способы создания Observable, которые различаются :
- Obvervable.just() — созданный Observable отправляет наблюдателям данные, переданные в аргументах just().
- Observable.fromIterable() — созданный Observable отправляет наблюдателям коллекцию или любой другой объект, реализующий интерфейс Iterable.
- Observable.fromArray() — созданный Observable отправляет наблюдателям массив или коллекцию. Различие между fromIterable() и fromArray() состоит в том, что в первом случае данные из коллекции отправляются поштучно, а во втором — все сразу.
- Observable.fromCallable() — созданный Observable отправляет наблюдателям объект, реализующий интерфейс Callable.
Кроме Observable также существуют и другие типы, являющиеся источниками событий.
- Single — содержит один элемент или возвращает ошибку.
- Completable — успешно завершает работу или возвращает ошибку.
- Maybe — содержит (или не содержит) один элемент или возвращает ошибку.
- Flowable — эквивалентен Observable, но используется для работы с большими объёмами данных.
В статье мы лишь поверхностно коснулись RxJava. На рассмотрение всего функционала может понадобиться не одна статья, т.к. данный фреймворк включает в себя большое количество различных классов и методов. Если вам интересна эта тема, можно обратиться к официальной документации, либо к различным статьям в Интернете:
- Документация по RxJava
- Документация по RxAndroid
- Многопоточность в мобильной разработке
- Что такое RxJava
- Android: RxJava
RxJava предоставляет мощный инструментарий для работы с асинхронными операциями и управлениями потоками данных. Однако он также имеет и ряд недостатков:
- Высокий порог вхождения. Чтобы понимать, как работает RxJava, нужно ознакомиться с работой большого количества новых для разработчика классов и методов. Ситуацию усугубляет и то, что библиотека с годами не стояла на месте: добавлялись новые классы, удалялись старые. В Интернете собрано огромное количество руководств по RxJava, но каждое из них написано на текущей для того времени версии библиотеки, что может не соответствовать актуальной версии и вносит дополнительную путаницу.
- RxJava это внешняя зависимость, она не является частью Android SDK или Java/Kotlin.
- Код, написанный с использованием RxJava, сложнее отлаживать.
Тем не менее, RxJava долгое время занимала лидирующую позицию среди фреймворков по работе с асинхронным кодом, и по сей день остаётся эффективным инструментом. Лишь относительно недавно её популярность начала спадать, поскольку появился новый инструмент, целью которого было делать всё те же операции, но в более лаконичном и удобном для чтения виде.
Kotlin Coroutines
С развитием языка Kotlin в нём появился такой механизм, как корутины (coroutines) или сопрограммы. На данный момент они занимают одну из лидирующих позиций среди остальных фреймворков, а Google продвигает их как стандарт при разработке приложений.
В общем смысле сопрограммы — это специальные функции, которые могут приостанавливать своё выполнение и передавать управление другим сопрограммам, а затем продолжать с того места, где остановились.
Корутины представляют собой легковесные потоки, которые выполняются в контексте реальных потоков и не создают дополнительную нагрузку на систему, т.к. не являются отдельными потоками. Один поток может запускать сразу несколько корутин.
Благодаря этому, корутины позволяют писать асинхронные программы, способные выполнять множество задач одновременно.
Сама идея корутин не нова, они используются в различных языках программирования либо как часть языка, либо на уровне библиотек. В случае с Kotlin, сопрограммы были реализованы на уровне языка, начиная с версии 1.3.
Сам по себе Kotlin предоставляет только минимальный низкоуровневый API для работы с корутинами. К примеру, в стандартной библиотеке Kotlin отсутствуют такие ключевые слова, как async и await. Она предоставляет только одно ключевое слово suspend, которая добавляется к объявлению функции. Функция, отмеченная как suspend, возвращает свой ответ асинхронно, и потому не может быть вызвана из обычной функции. Такую функцию можно вызвать только из другой suspend функции или из корутины. Основная магия здесь заключается в том, что во время компиляции suspend функция преобразовывается и становится асинхронной.
Чтобы получить весь функционал для работы, помимо стандартной библиотеки Kotlin нужно подключить библиотеку kotlinx.coroutines, которая содержит в себе высокоуровневые классы по работе с сопрограммами. В свою очередь kotlinx.coroutines предоставляет два артефакта:
- kotlinx-corounites-core — предоставляет все основные классы и методы для работы с корутинами.
- kotlinx-coroutines-android — расширяет основной функционал, добавляя специфичные классы для работы с корутинами на Android.
В Android корутины помогают управлять длительными задачами, которые в противном случае могут заблокировать главный поток.
Основная цель появление корутин в Kotlin — написание асинхронного кода в синхронном стиле. Нет необходимости создавать методы обратного вызова, все вызовы можно делать последовательно, как если бы мы использовали обычные функции.
Каждая корутина привязана к определённому жизненному циклу (scope). К примеру, в рамках Android-приложения жизненный цикл начинается при запуске экрана и заканчивается, пользователь выходит из него. И при завершении этого жизненного цикла все корутины, которые были к нему привязаны, остановятся, что позволяет избегать утечек памяти при работе с ними.
Попробуем написать простую корутину, которая имитирует длительную работу и возвращает результат. Запустить сопрограмму можно с помощью одной из трёх специальных функций-билдеров. Одной из них является CoroutineScope.launch(). Однако для этого нам нужно как-то получить CoroutineScope (о том, что это такое, мы поговорим чуть позже). Можно воспользоваться специальным классом GlobalScope, но делать этого не рекомендуется: авторы советуют использовать этот scope лишь в самых крайних случаях, а лучше не использовать вовсе. Оставим его лишь в качестве примера.
GlobalScope.launch {
val result = doWork()
withContext(Dispatchers.Main) {
binding.tvResult.text = result
}
}Казалось бы, если нет scope, то как запустить корутину? В библиотеке есть специальный метод runBlocking(), который служит мостиком между блокирующим кодом и корутинами. Он блокирует поток, из которого был вызван, до тех пор, пока корутины не завершат свою работу, и предоставляет scope, который может запустить корутину. Из-за блокировки потока этот метод рекомендуется использовать в редких случаях, например в тестах или когда корутину нужно выполнить из main функции.
private fun createCoroutine() {
runBlocking {
launch {
val result = doWork()
binding.tvResult.text = result
}
}
}
private suspend fun doWork(): String {
delay(5000L)
return "Hello from coroutine ${Thread.currentThread().name}!"
}Мы объявили suspend функцию, в которой имитируем какую-то работу, после чего возвращаем сообщение. Метод delay(Long) позволяет приостановить работу корутины на заданное время.
Когда корутина завершит свою работу, поток освободится и на экране мы увидим сообщение.
Также есть ещё один способ создать корутину через функцию async(). Она аналогична launch(), но возвращает значение типа Deferred. Запустить такую корутину можно через через вызов метода await().
runBlocking {
val coroutine = GlobalScope.async {
delay(5000L)
"Hello from coroutine ${Thread.currentThread().name}!"
}
binding.tvResult.text = coroutine.await()
}Как мы уже упоминали выше, для запуска корутины нужен некий CoroutineScope, к которому она будет привязана.
CoroutineScope представляет собой жизненный цикл асинхронной операции. Это один из основных компонентов для управления корутинами, т.к. он предоставляет API для запуска и отмены корутин и позволяет определять поток, на котором та должна выполняться.
Если обратиться к исходникам, то можно увидеть, что CoroutineScope является интерфейсом, содержащим всего лишь один объект CoroutineContext. Этот объект является очень важным в работе корутин, поскольку он хранит всю информацию о запущенной корутине. Контекст также определяет, как именно должна быть запущена корутина. Как правило, CoroutineContext создаётся автоматически, исходя из текущего scope, поэтому разработчикам не нужно о нём заботиться.
То есть, каждая корутина имеет свой CoroutineContext с набором параметров для выполнения, CoroutineScope в свою очередь определяет жизненный цикл этих корутин и объединяет все запущенные в рамках него корутины.
Ранее мы уже использовать один из таких scope под названием GlobalScope. Это глобальный CoroutineScope, который не связан с жизненным циклом компонентов Android и продолжает свою работу до тех пор, пока жив процесс приложения. Из-за этого его не рекомендуется использовать в реальных проектах, т.к. неправильная работа с корутинами в этом случае приведёт к утечкам памяти и появлению ошибок.
Однако для Android существуют другие уже готовые CoroutineScope:
- viewModelScope — CoroutineScope, который связан с жизненным циклом ViewModel. Он работает до тех пора, пока не будет уничтожена ViewModel.
- lifecycleScope — CoroutineScope, который связан с жизненным циклом объекта, реализующего LifecycleOwner. Как правило, к таким объектам относятся активности и фрагменты.
Благодаря этим двум CoroutineScope мы можем использовать корутины, не боясь, что они переживут жизненных цикл указанных компонентов и продолжат выполнение операций.
Вернёмся к нашему примеру. Поскольку мы пишем код в фрагменте, то можем заменить runBlocking() на lifecycleScope, что уберёт блокировку потока.
private fun createCoroutine() {
binding.progress.visibility = View.VISIBLE
binding.tvResult.visibility = View.INVISIBLE
lifecycleScope.launch {
val result = doWork()
binding.progress.visibility = View.INVISIBLE
binding.tvResult.visibility = View.VISIBLE
binding.tvResult.text = result
}
}
private suspend fun doWork(): String {
delay(5000L)
return "Hello from coroutine ${Thread.currentThread().name}!"
}Теперь наш поток не блокируется и мы можем увидеть прогресс ожидания и обновления UI.
Можно также создать свой собственный CoroutineScope, однако стоит быть осторожным, потому что в этом случае мы должны самостоятельно отслеживать и отменять корутины. Это может быть полезно в случаях, когда нужно создать определённую область для работы корутин или жизненный цикл в конкретно взятом компоненте.
Подводя итог, основные принципы CoroutineScope заключаются в следующем:
- Отмена scope — отмена всех дочерних корутин.
- Scope знает про все корутины, запущенные в нём.
- Scope ожидает завершение всех дочерних корутин, но сам после этого может продолжить свою работу.
Эти принципы объединяются в общий механизм, называемый Structured concurrency.
Structured concurrency — это механизм, предоставляющий иерархическую структуру для организации работу корутин.
CoroutineScope.launch() возвращает объект типа Job. Job это один из базовых классов, который хранит результат запуска корутины. Поэтому каждая сопрограмма является Job.
Интерфейс Job предоставляет методы для управления жизненным циклом сопрограммы. Он также хранит текущее состояние корутины, которое может быть одним из перечисленных ниже:
- New
- Active
- Completing
- Cancelling
- Cancelled
- Completed
Запуск через билдер CoroutineScope.async() в свою очередь возвращает объект Deffered, который наследует от Job, и принимает в качестве параметра тип результата.
CoroutineScope содержит свой собственный Job, задачей которого является объединение всех других Job, запущенных в данной области.
Поскольку Job может включать в себя другие Job, то на основе этого можно строить иерархию корутин.
Если Job отменяется, то также рекурсивно отменяются все дочерние Job. Аналогично, если в одной из дочерних Job произойдёт ошибка, то это вызовет отмену родительских Job.
Как мы уже говорили, CoroutineContext содержит в себе всю информацию о текущей корутине. В том числе он будет содержать и Job сопрограммы. Также контекст корутины содержит и информацию о том, на каком потоке должна работать корутина.
Такая информация хранится в специальном объекте типа CoroutineDispatcher. Он то и определяет, какой поток должна использовать корутина. Диспетчер может ограничить выполнение корутины определенным потоком, отправить её в другой пул потоков или позволить выполняться без ограничений. Выбор правильного диспетчера важен, т.к. позволяет эффективно применять ресурсы и предотвращать блокировку UI-потока. Под капотом CoroutineDispatcher находится механизм Executor, о котором мы рассказывали ранее. Он позволяет диспетчерам организовывать пул потоков и запускать на них корутины.
Есть несколько стандартных диспетчеров, определённых в классе Dispatchers:
- Default — стандартный диспетчер, который используется корутинами, если не был явно указан какой-либо другой. Используется для интенсивных вычислительных операций или переноса задач в фоновый поток. Количество потоков в пуле соответствует количеству ядер в процессоре.
- Main — выполняет работу на главном потоке Android. Он применяется для всех операций, обновляющих UI.
- Unconfined — не привязан к какому-либо потоку. Выполнение корутины в этом случае происходит в том же потоке, в котором происходило её создание и запуск. Используется в случаях, когда нам не нужно менять поток для выполнения корутины.
- IO — предназначен для I/O операций на специально выделенном пуле потоков. По умолчанию количество потоков равно количеству ядер процессора.
Примечание: часто можно обнаружить советы, в которых говорится о том, чтобы не использовать стандартные диспетчеры как есть. Вместо этого лучше создать отдельную класс-обёртку, в которой они будут переопределены. Делается это для того, чтобы в дальнейшем можно было легко подменить диспетчеры на какие-либо другие, если появится необходимость в создании своего диспетчера.
class AppDispatchers(
val main: MainCoroutineDispatcher = Dispatchers.Main,
val default: CoroutineDispatcher = Dispatchers.Default,
val io: CoroutineDispatcher = Dispatchers.IO,
val unconfined: CoroutineDispatcher = Dispatchers.Unconfined
)Когда мы вызываем CoroutineScope.launch() без параметров, то новая корутина наследует контекст (а также и диспетчер) от того CoroutineScope, внутри которого запускается. Чтобы явно указать, на каком потоке мы хотим выполнить операцию, нужно в параметры launch() передать требуемый диспетчер.
Вернёмся к нашему примеру и запустим его в IO диспетчере.
lifecycleScope.launch(Dispatchers.IO) {
val result = doWork()
binding.progress.visibility = View.INVISIBLE
binding.tvResult.visibility = View.VISIBLE
binding.tvResult.text = result
}Если мы запустим этот код. то suspend функция отработает, однако после неё произойдёт креш. Это вызвано тем, что мы пытаемся обновить UI не из главного потока. Что же делать в этом случае?
Если нужно для какого-то кода сменить контекст корутины, не запуская при этом новую, то можно воспользоваться функцией withContext(CoroutineContext). К примеру, эта функция используется для смены диспетчера в корутине, создавая новый контекст при комбинировании текущего и переданного диспетчера.
Добавим его в наш пример. Поскольку нам нужно обновить UI, то переключить контекст следует на Dispatchers.Main.
lifecycleScope.launch(Dispatchers.IO) {
val result = doWork()
withContext(Dispatchers.Main) {
binding.progress.visibility = View.INVISIBLE
binding.tvResult.visibility = View.VISIBLE
binding.tvResult.text = result
}
}Теперь наша корутина отрабатывает как надо, обновляет UI и не приводит к крешам.
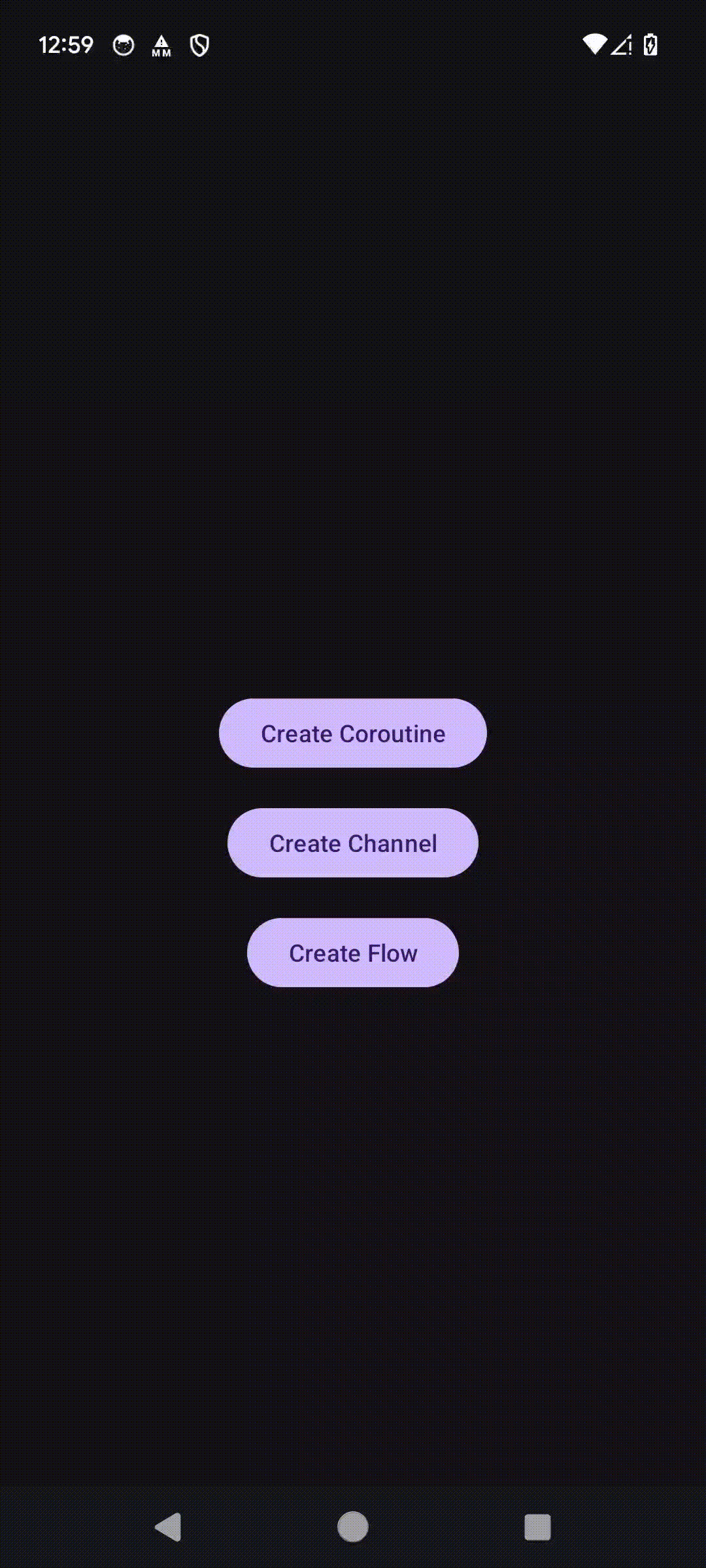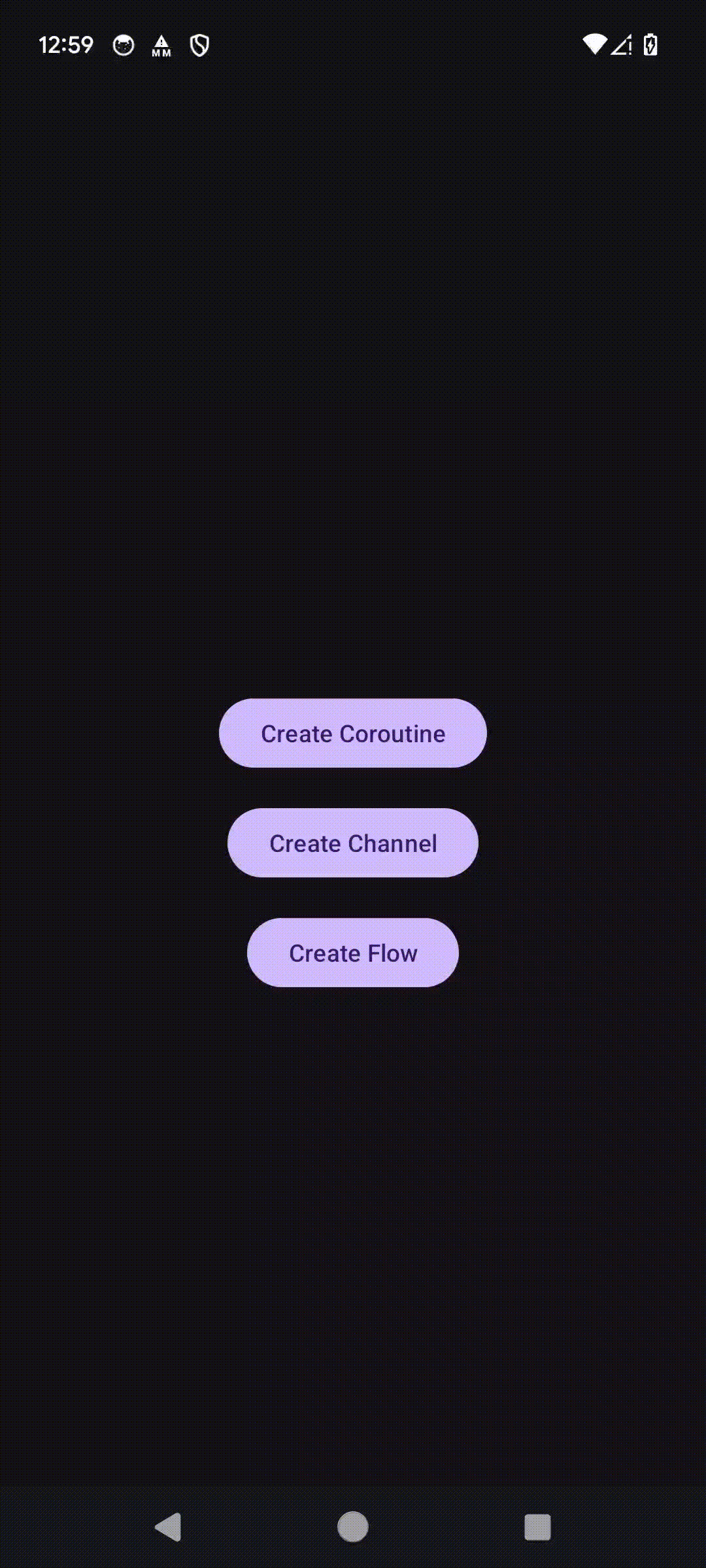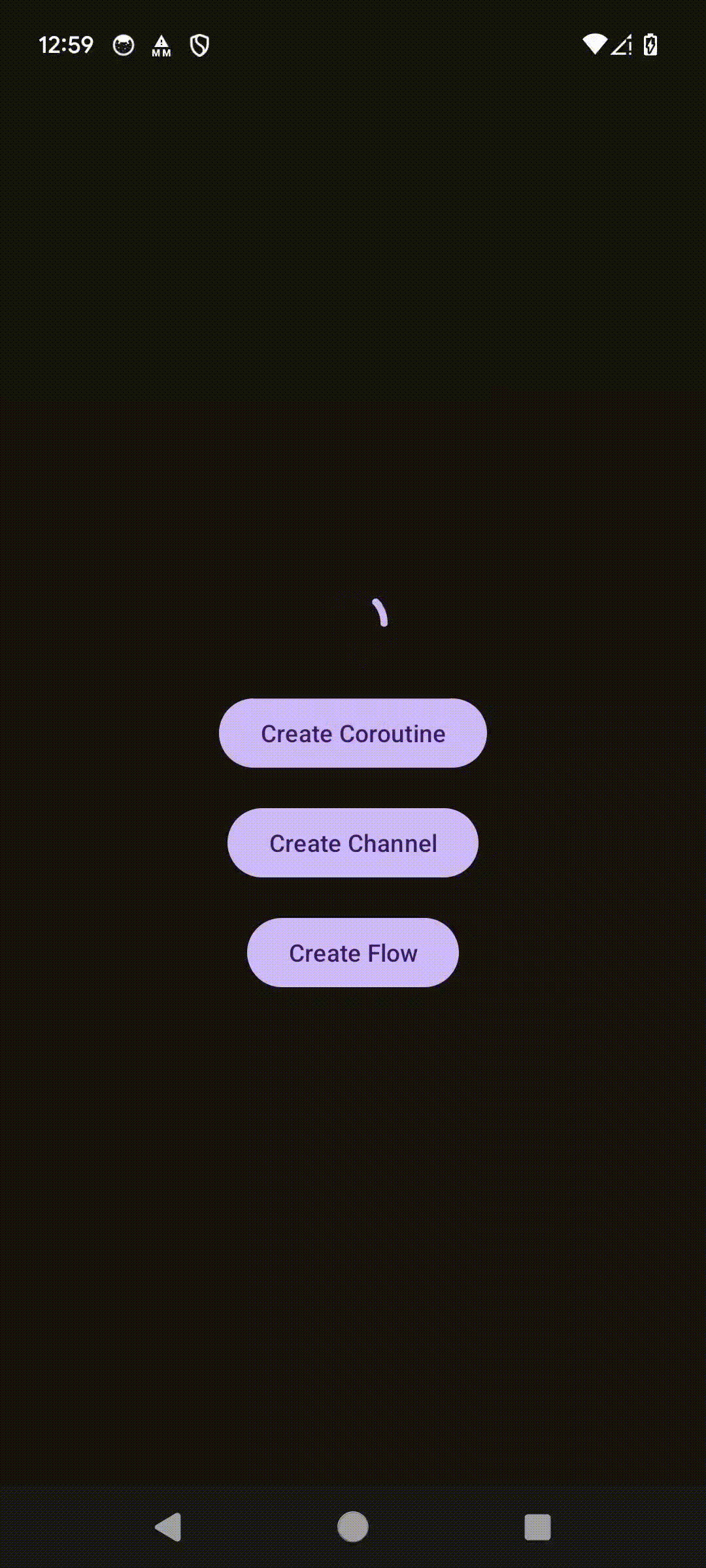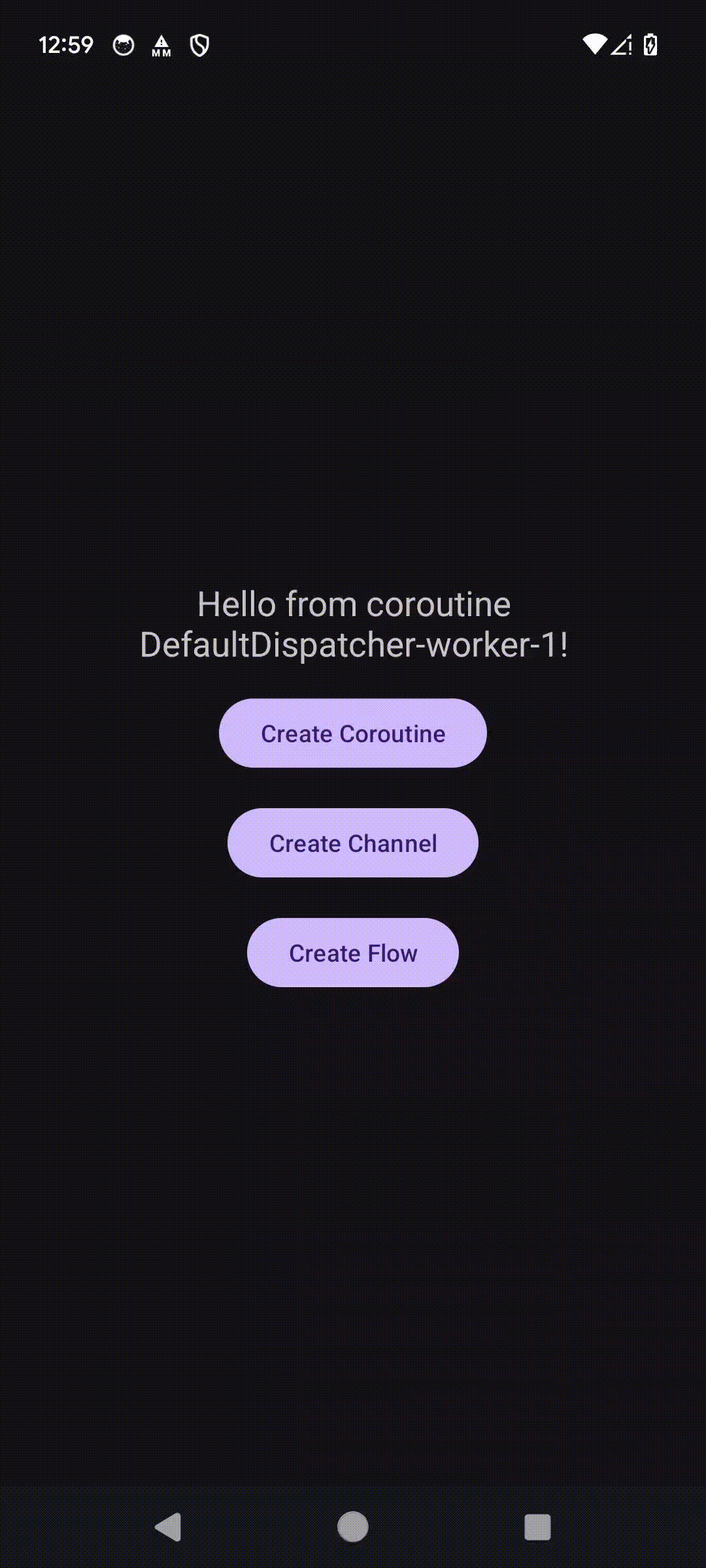
При необходимости можно не задавать какой-то диспетчер, а вызвать корутину на отдельном созданном потоке. Сделать это можно с помощью метода newSingleThreadContext(String), в параметры которого нужно передать имя потока. Данный метод гарантирует, что корутина будет выполняться только в этом потоке. Однако важно учитывать, что создание новых потоков это дорогостоящая операция и при завершении работы корутины поток следует освободить или переиспользовать для других корутин.
lifecycleScope.launch(newSingleThreadContext("Test thread 1")) {
val result = doWork()
withContext(Dispatchers.Main) {
binding.progress.visibility = View.INVISIBLE
binding.tvResult.visibility = View.VISIBLE
binding.tvResult.text = result
}
}Кроме того, мы можем задать корутине конкретное имя. Это упрощает отладку приложения, позволяя определять, где какая корутина у нас запущена. Чтобы сделать это, нужно к контексту корутины добавить имя с помощью класса CoroutineName(String).
lifecycleScope.launch(CoroutineName("Test coroutine") + Dispatchers.IO) {
val result = doWork()
withContext(Dispatchers.Main) {
binding.progress.visibility = View.INVISIBLE
binding.tvResult.visibility = View.VISIBLE
binding.tvResult.text = result
}
}Теперь во время отладки мы можем получить контекст нашей корутины и увидеть там заданное имя.
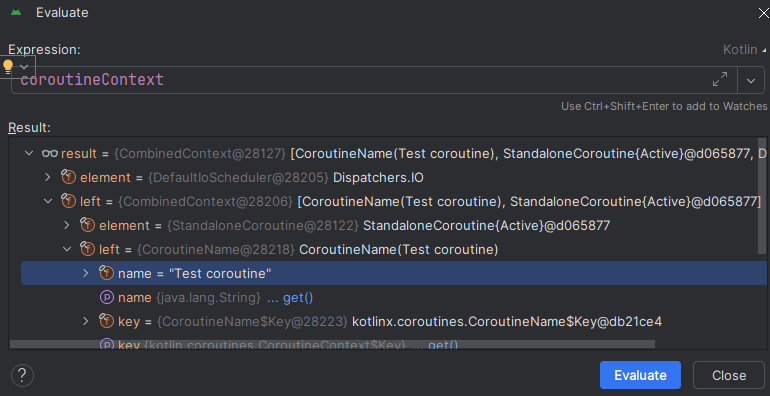
Чтобы обрабатывать ошибки в корутинах, можно воспользоваться стандартной реализацией try-catch. Однако она может различаться для вызовов launch() и async().
runBlocking {
/* Вариант с launch() */
launch(Dispatchers.IO) {
try {
doWork()
} catch (e: Exception) {
// Обрабатываем исключение
}
}
/* Вариант с async() */
val deferred = async(Dispatchers.IO) {
doWork()
}
try {
deferred.await()
} catch (e: Exception) {
// Обрабатываем исключение
}
}В случаях, если корутина выполняет длительную операцию, которая уже не нужна, то её следует отменить. Сделать это можно с помощью метода Job.cancel().
Отмена корутины выбрасывает исключение CancellationExeption — специальное исключение для обработки отмены выполнения корутин.
Важно! Если вы хотите обрабатывать это исключение в корутинах, то нужно обязательно выделять его в отдельную ветку и после обработки пробрасывать дальше. Если этого не сделать, то это нарушит механизм работы корутин.
runBlocking {
launch(Dispatchers.IO) {
try {
doWork()
} catch (e: Exception) {
// Обрабатываем исключение
} catch (e: CancellationException) {
// Обрабатываем и пробрасываем дальше
throw e
}
}
}До сих пор мы рассматривали корутины, которые просто выполняют задачи и никак не взаимодействуют с другими корутинами.
Для взаимодействия между корутинами в Kotlin присутствует такой механизм как каналы (Channel).
Каналы похожи на BlockingQueue в Java, но построены на основе корутин и поэтому имеют механизм приостановки.
Channel<E> представляет собой интерфейс, который реализует два других интерфейса: SendChannel<E> и ReceiveChannel<E>. Те, в свою очередь, содержат методы по отправке сообщений в канал send(E) и получении сообщений из канала receive() соответственно.
Канал работает до тех пор, пока не будет вызван метод Channel.close(), закрывающий его.
Напишем пример с двумя корутинами. Первая будет отправлять сообщение в канал, а вторая, после некоторого ожидания, получать его и выводить на экран.
private fun createChannel() {
binding.progress.visibility = View.VISIBLE
binding.tvResult.visibility = View.INVISIBLE
val channel = Channel()
lifecycleScope.launch(Dispatchers.IO) {
val message = "Hello from coroutine ${Thread.currentThread().name}!"
channel.send(message)
}
lifecycleScope.launch(Dispatchers.IO) {
delay(3000L)
val message = channel.receive()
withContext(Dispatchers.Main) {
binding.progress.visibility = View.INVISIBLE
binding.tvResult.visibility = View.VISIBLE
binding.tvResult.text = message
channel.close()
}
}
} Благодаря каналам, корутины могут получить данные извне. Также каналы помогают организовывать работу сразу нескольких корутин.
В главе про RxJava мы рассказывали о такой парадигме как реактивное программирование, позволяющее реагировать на события и обрабатывать их. Такой механизм тоже реализован в корутинах в виде реактивных потоков Flow.
Flow — это асинхронный поток данных, который последовательно выдаёт значения и завершается успешно или с ошибкой. Flow является холодным потоком, т.е. выдаёт значения только при запуске.
Flow представляет собой простой интерфейс, который содержит в себе suspend функцию, принимающую в качестве параметра FlowCollector<T>, collect(FlowCollector<T>). FlowCollector в свою очередь это интерфейс, содержащий suspend функцию emit(T). Задача функции collect() это запуск получения данных из Flow.
Вся остальная работа с Flow реализована через функции расширения, которые предоставляют нужные операции по работе с потоками данных. Это позволяет расширять Flow до необходимых размеров, не усложняя при этом базовый интерфейс.
Создать Flow можно следующими способами:
- flowOf()
flowOf(1)
flowOf("a", "b", "c", "d")
listOf("a", "b", "c", "d").asFlow()- flow()
flow {
emit(1)
}Промежуточные методы преобразования Flow принимают на вход Flow<T>, выполняют над ним нужные операции, после чего передают дальше преобразованный Flow<R>. Промежуточные оператора сами по себе не выполняют никаких операций, они только настраивают цепочку операций, которая будет запущена при старте потока данных.
Напишем небольшой пример, аналогичный примеру в RxJava, который создаёт поток данных и эмитит новые значения каждую секунду.
private fun createFlow() {
binding.tvResult.visibility = View.VISIBLE
lifecycleScope.launch(Dispatchers.IO) {
flow {
while (true) {
delay(1000L)
emit(Date())
}
}.collect { date ->
withContext(Dispatchers.Main) {
binding.tvResult.text = date.toString()
}
}
}
}
Как мы уже упоминали, Flow представляет собой холодный поток. Однако в Kotlin есть возможность создавать и горячие потоки, которые начинают работать сразу при их создании.
Для этого существуют отдельные реализации Flow под названием SharedFlow и StateFlow.
SharedFlow — бесконечный поток данных, который эмитит значения всем своим подписчикам.
SharedFlow содержит в себе буфер, который состоит из двух частей:
- Replay cache — элементы доставляются новый подписчикам.
- Extra buffer — элементы сохраняются при наличии подписчиков, когда не могут быть доставлены сразу же.
Мы можем настраивать параметры этого буфера для оптимальной работы потока данных.
StateFlow — это частный случай SharedFlow, имеющий replay cache =1 и extra buffer = 0. Он хранит одно значение и доставляет его всем свои подписчикам. Новое значение будет доставлено только в том случае, если оно отличается от старого.
Благодаря этим потокам данных мы можем писать реактивный код, как это было бы в случае с RxJava. Авторы корутин также добавили аналоги методов из RxJava для того, чтобы упростить миграцию на корутины.
Мы рассмотрели лишь самые основные компоненты корутин, не затрагивая некоторые аспекты и не углубляясь в механизм работы корутин под капотом. Если вы хотите, вы можете это изучить в официальной документации или в различных статьях:
- Официальная документация по Kotlin
- Перевод документации на русском
- Документация на Android Developers
- Видео-курс по корутинам от Android Broadcast
- Многопоточность в мобильной разработке
- Kotlin Coroutines. Часть 1: Первое погружение
- Ликбез по корутинам Kotlin
- Работа с асинхронными операциями с помощью Kotlin Coroutines
- Kotlin Coroutines под капотом
Корутины представляют собой очень мощный инструмент. Интеграция его как часть языка, предоставление удобного API, сокрытие колбэков под капотом и улучшение производительности за счёт легковесных потоков в итоге привели к тому, что сейчас сопрограммы используются в большинстве приложений и их популярность только растёт.
Заключение
Мы рассмотрели самые разные механизмы организации многопоточности в Android-приложениях. Какие-то способы в настоящее время уже редко встретишь, какие-то фактически устарели и не рекомендуются к использованию, какие-то до сих пор актуальны. Развитие каждой новой технологии происходило с учётом недостатков предыдущей, что позволило современным разработчикам писать асинхронный код на более высоком уровне, не задумываясь о том, как оно всё устроено внутри.
В статье нет рекомендаций по выбору какого-то одного механизма, каждый из них имеет свои особенности, которые могут стать решающими при выполнении конкретных задач.