
В октябрьском номере журнала за 2013 год, есть задачи с собеседований, которые собрал Крис Касперски.
Решением первой задачи и хочу поделиться сегодня в 2018 году.
Текст задачи :
Дается двоичный файл и предлагается ответить на вопрос, как неофициально называется место, в котором при успешном прохождении собеседования предстоит работать. В hex-виде содержимое файла выглядит так:
78 9C 0B 4F CD 49 CE CF 4D 55 28 C9 57 28 C9 48
55 F0 C8 2C 4B 55 54 54 E4 E5 02 00 69 AB 07 57
Текст английский, кодировка UTF8. Если возникнет желание решить задачу методом перебора, то вот наиболее полные словари английского языка в plain-text формате: bit.ly/a8OvW7 .
Решение :
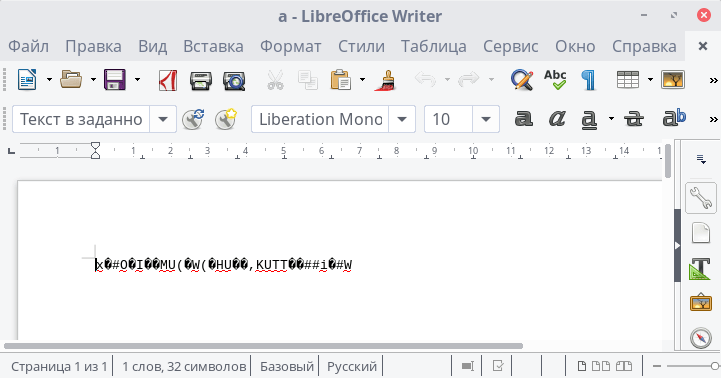
Нижний комментарий был дан авторами для отвода от нужного следа. Ссылка на словарь уже давно не работает. Да и если представить что перед нами просто текст в UTF-8, то получим что-то вроде этого :
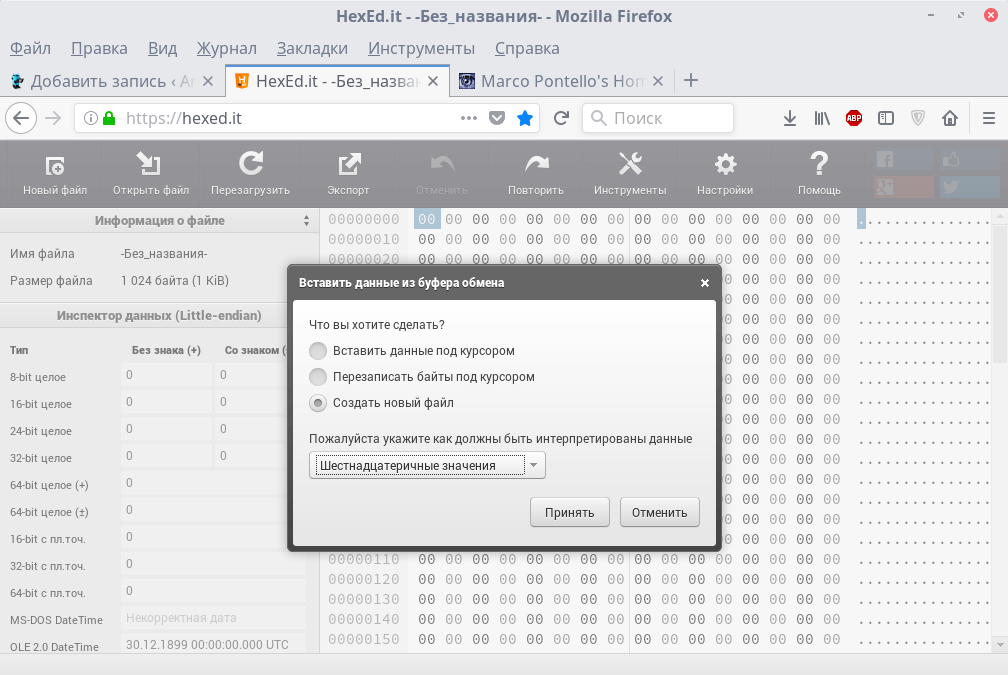
Для дальнейшего решения нужно просто создать сам файл. Для редактирования Hex файлов есть vim и прочие динозавры, но нам достаточно онлайн редактора https://hexed.it/
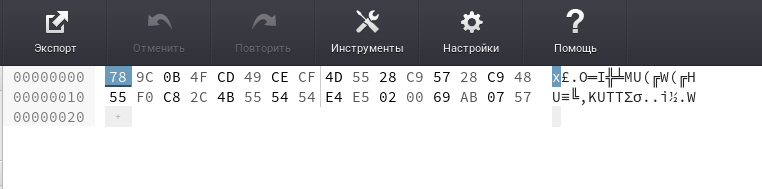
В правом столбце редактор так же пытается показать какой-то вразумительный текст, но безуспешно :
Выгрузим полученный файл и определим его тип в онлайн сервисе Online TrID File Identifier
Результат работы сервиса :
 Дело осталось за малым, нужно распаковать данные, которые упаковали библиотекой ZLIB .
Дело осталось за малым, нужно распаковать данные, которые упаковали библиотекой ZLIB .
На Linux для этого нужно установить пакет qpdf в Fedora это делается одной строчкой в терминале :
sudo dnf install qpdf
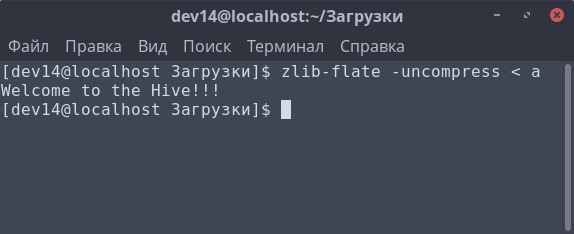
А дальше остается только выполнить команду zlib-flate с параметром -uncompress и именем файла .
Вот и ответ на задачу :
Привет, подскажи, какой дистрибутив Linux используешь?
Привет. Fedora